
SQL/Bigquery文本分类
SQL/Bigquery文本分类
提问于 2020-11-17 18:35:04
我需要使用regex实现一个简单的文本分类,为此,我想在语句时应用一个简单的情况,但是在满足情况1条件的情况下,我想迭代所有的情况。
例如
with `table` as(
SELECT 'It is undeniable that AI will change the landscape of the future. There is a frequent increase in the demand for AI-related jobs, especially in data science and machine learning positions. It is believed that artificial intelligence will change the world, just like how electricity changed the world about 100 years ago. As Professor Andrew NG has famously stated multiple times “Artificial Intelligence is the new electricity.” We have advanced immensely in the field of artificial intelligence. With the increase in the processing and computational power, thanks to graphical processing units (GPUs), and also due to the abundance of data, we have reached a position of supremacy in Deep Learning and modern algorithms.' as text
)
SELECT
CASE
WHEN REGEXP_CONTAINS(text, r'(?i)ai') THEN 'AI'
WHEN REGEXP_CONTAINS(text, r'(?i)computational power') THEN 'Engineering'
WHEN REGEXP_CONTAINS(text, r'(?i)deep learning') THEN 'Deep Learning'
END as topic,
text
FROM `table`通过这个查询,文本被归类为AI,因为它是满足的第一个条件,但是它应该被归类为数组中的AI、Engineering和深度学习,或者是在三个不同的行中,因为这三个条件都满足了。
如何分类应用所有正则/条件的文本?
回答 3
Stack Overflow用户
回答已采纳
发布于 2020-11-17 19:08:34
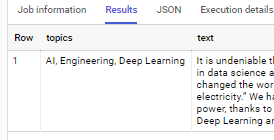
我觉得下面是最通用和最可重用的解决方案(BigQuery标准SQL)
#standardSQL
with `table` as(
select 'It is undeniable that AI will change the landscape of the future. There is a frequent increase in the demand for AI-related jobs, especially in data science and machine learning positions. It is believed that artificial intelligence will change the world, just like how electricity changed the world about 100 years ago. As Professor Andrew NG has famously stated multiple times “Artificial Intelligence is the new electricity.” We have advanced immensely in the field of artificial intelligence. With the increase in the processing and computational power, thanks to graphical processing units (GPUs), and also due to the abundance of data, we have reached a position of supremacy in Deep Learning and modern algorithms.' as text
), classification as (
select 'ai' term, 'AI' topic union all
select 'computational power', 'Engineering' union all
select 'deep learning', 'Deep Learning'
), pattern as (
select r'(?i)' || string_agg(term, '|') as regexp_pattern
from classification
)
select
array_to_string(array(
select distinct topic
from unnest(regexp_extract_all(lower(text), regexp_pattern)) term
join classification using(term)
), ', ') topics,
text
from `table`, pattern 带输出
Stack Overflow用户
发布于 2020-11-17 18:37:56
一种方法是字符串连接:
SELECT CONCAT(CASE WHEN REGEXP_CONTAINS(text, r'(?i)ai') THEN 'AI;' ELSE '' END,
CASE WHEN REGEXP_CONTAINS(text, r'(?i)computational power') THEN 'Engineering;' ELSE '' END,
CASE WHEN REGEXP_CONTAINS(text, r'(?i)deep learning') THEN 'Deep Learning;' ELSE '' END
) as topics, text
FROM `table`;实际上,它构造了一个字符串。您可以使用类似的ish逻辑来构造数组。
Stack Overflow用户
发布于 2020-11-17 18:49:46
下面是用于BigQuery标准SQL的
#standardSQL
select
array_to_string(array(select distinct lower(topic)
from unnest(regexp_extract_all(text, r'(?i)ai|computational power|deep learning')) topic
), ', ') topics,
text
from `table` 如果要应用于问题输出中的样本数据,请参见

页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64881264
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号