
熊猫数据组合/组合栏?
我对Pandas很陌生,弄清楚数据集的时间也很糟糕。我在使用pandas.read_csv,dogData中读到了一个csv文件,如下所示:
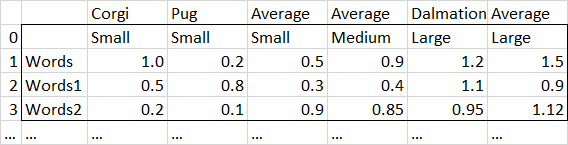
列名是狗的品种,第一行指的是狗的大小,除此之外还有一堆数值。第一列有我需要保留的字符串描述,但与问题无关。每个大小类别的最后一列包含单独的“平均值”值。(注意,它将“Average.1”、"Average.2“等列改为"Average.1",以照顾它们不是唯一的)
基本上,我想按第一行“分组”-所以所有的“小”狗值都将被平均,除了“小”平均列,等等。结果会是这样的:
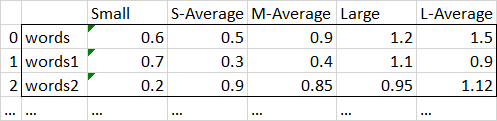
现有的“平均”列不应包括在正在计算的新平均值中。每个大小的现有“平均”列根本不需要更改。所有“小”品种值应平均,所有“中等”品种值应平均,依此类推(实际文件比我在这里展示的示例大得多)。
不能保证品种不会被改变,也不能保证“大小”保持不变/总是被包括在内(例如,“小”可能被忽略)。
编辑:在Joe的评论之后,我已经更新了我的代码,并有了一些更接近于工作的内容,但是实际添加的列给我带来了麻烦。
dogData = pd.read_csv("dogdata.csv", header=[0,1])
dogData.columns = dogData.columns.map("_".join)
totalVal = ""
count = 0
for col in dogData:
if "Unnamed" in col:
continue # to skip starting columns
if "Average" not in col:
totalVal += dogData[col]
count += 1
else:
# this is where I'd calculate average, then reset count and totalVal
# right now, because the addition isn't working, I'm haven't figured that out
break
print(totalVal)现在,这段代码在技术上得到了正确的值..。但是它不允许我在数字上添加它们(因此totalVal现在是一个字符串)。它给了我一串级联的数字,正确的级联数字,但不允许我将它们转换为浮动以实际添加。
我尝试过为float(dogData[col])加法行做totalVal --它给了我一个TypeError: cannot convert the series to <class float>
我试着把它保持为字符串,在数字之间插入",“,然后执行totalVal.split(",")将它们分开,然后转换和添加.但很明显这也不起作用,因为AttributeError: 'Series' has no attribute 'split'
这些错误对我来说是有意义的,我理解为什么会发生这些错误,但我不知道正确的方法是什么。dogData[col]一次给出每一行的所有值,这正是我想要的,但我不知道如何存储它,并将其添加到循环的下一次迭代中。
以下是数据的副本/可传递示例:
,Corgi,Yorkie,Pug,Average,Average,Dalmation,German Shepherd,Average,Great Dane,Average
,Small,Small,Small,Small,Medium,Large,Large,Large,Very Large,Very Large
Words,1,3,3,3,2.4,3,5,7,7,7
Words1,2,2,4,4,2.2,4,4,6,8,8
Words2,2,1,5,3,2.5,5,3,8,9,6
Words3,1,4,4,2,2.7,6,6,5,6,9 回答 1
Stack Overflow用户
发布于 2020-11-19 04:22:04
你得做些小把戏才能让这件事起作用。步骤1:您需要读取csv文件并使用前两行作为头。它将创建一个MultiIndex列列表。
步骤2:您需要将它们与_一起加入。
步骤3:然后根据需要重命名特定的列,如Step,M-Average,.
步骤4:找出有多少列有狗名+小
步骤5:计算小值。根据req,sum (列与小)/ count (列与小)
步骤6.7:对大型用户进行同样的操作
步骤8,9:对非常大的
这会给你最后的名单。如果希望列按特定顺序排列,则可以更改顺序。
步骤10:更改dataframe的顺序
import pandas as pd
df = pd.read_csv('abc.txt',header=[0,1], index_col=0)
df.columns = df.columns.map('_'.join)
df.rename(columns={'Average_Small': 'S-Average',
'Average_Medium': 'M-Average',
'Average_Large': 'L-Average',
'Average_Very Large': 'Very L-Average'}, inplace = True)
idx = [i for i,x in enumerate(df.columns) if x.endswith('_Small')]
if idx:
df['Small']= ((df.iloc[:, idx].sum(axis=1))/len(idx)).round(2)
df.drop(df.columns[idx], axis = 1, inplace = True)
idx = [i for i,x in enumerate(df.columns) if x.endswith('_Large')]
if idx:
df['Large']= ((df.iloc[:, idx].sum(axis=1))/len(idx)).round(2)
df.drop(df.columns[idx], axis = 1, inplace = True)
idx = [i for i,x in enumerate(df.columns) if x.endswith('_Very Large')]
if idx:
df['Very_Large']= ((df.iloc[:, idx].sum(axis=1))/len(idx)).round(2)
df.drop(df.columns[idx], axis = 1, inplace = True)
df = df[['Small', 'S-Average', 'M-Average', 'L-Average', 'Very L-Average', 'Large', 'Very_Large', ]]
print (df)这方面的产出如下:
Small S-Average M-Average ... Very L-Average Large Very_Large
Words 2.33 3 2.4 ... 7 4.0 7.0
Words1 2.67 4 2.2 ... 8 4.0 8.0
Words2 2.67 3 2.5 ... 6 4.0 9.0
Words3 3.00 2 2.7 ... 9 6.0 6.0https://stackoverflow.com/questions/64901983
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号