
如何在堆叠条形图中添加样本号,并检查R中的意义?
如何在堆叠条形图中添加样本号,并检查R中的意义?
提问于 2020-11-21 11:45:38
我有一个dataframe df,如下所示:
df <- structure(list(Samples = c("sample1", "sample2", "sample3", "sample4",
"sample5", "sample6", "sample7", "sample8", "sample9", "sample10",
"sample11", "sample12", "sample13", "sample14", "sample15", "sample16",
"sample17", "sample18", "sample19", "sample20", "sample21", "sample22",
"sample23", "sample24", "sample25", "sample26", "sample27", "sample28",
"sample29", "sample30", "sample31", "sample32", "sample33", "sample34",
"sample35", "sample36", "sample37", "sample38", "sample39", "sample40",
"sample41", "sample42"), new = c("Clus1", "Clus1", "Clus1", "Clus1",
"Clus1", "Clus1", "Clus1", "Clus1", "Clus1", "Clus1", "Clus1",
"Clus1", "Clus1", "Clus1", "Clus1", "Clus1", "Clus1", "Clus1",
"Clus1", "Clus1", "Clus1", "Clus1", "Clus1", "Clus1", "Clus1",
"Clus1", "Clus1", "Clus1", "Clus2", "Clus2", "Clus2", "Clus2",
"Clus2", "Clus2", "Clus2", "Clus2", "Clus2", "Clus2", "Clus2",
"Clus2", "Clus2", "Clus2"), Groups = c("GroupB", "GroupF", "GroupC",
"GroupD", "GroupF", "GroupD", "GroupA", "GroupC", "GroupE", "GroupD",
"GroupB", "GroupE", "GroupF", "GroupC", "GroupC", "GroupC", "GroupA",
"GroupA", "GroupA", "GroupE", "GroupC", "GroupB", "GroupC", "GroupC",
"GroupF", "GroupB", "GroupF", "GroupF", "GroupE", "GroupA", "GroupD",
"GroupE", "GroupF", "GroupB", "GroupD", "GroupD", "GroupE", "GroupE",
"GroupD", "GroupD", "GroupE", "GroupD")), row.names = c(NA, -42L
), class = c("tbl_df", "tbl", "data.frame"))利用上述数据,我绘制了一个叠加条形图:
group.colors <- c("GroupA"="skyblue","GroupB"="brown", "GroupC"="purple", "GroupD"="darkblue",
"GroupE"="darkgreen", "GroupF"="#FF8D00")
ggplot(df,aes(x = new,fill = Groups)) +
geom_bar() +
scale_fill_manual(values=group.colors)这个数字如下:
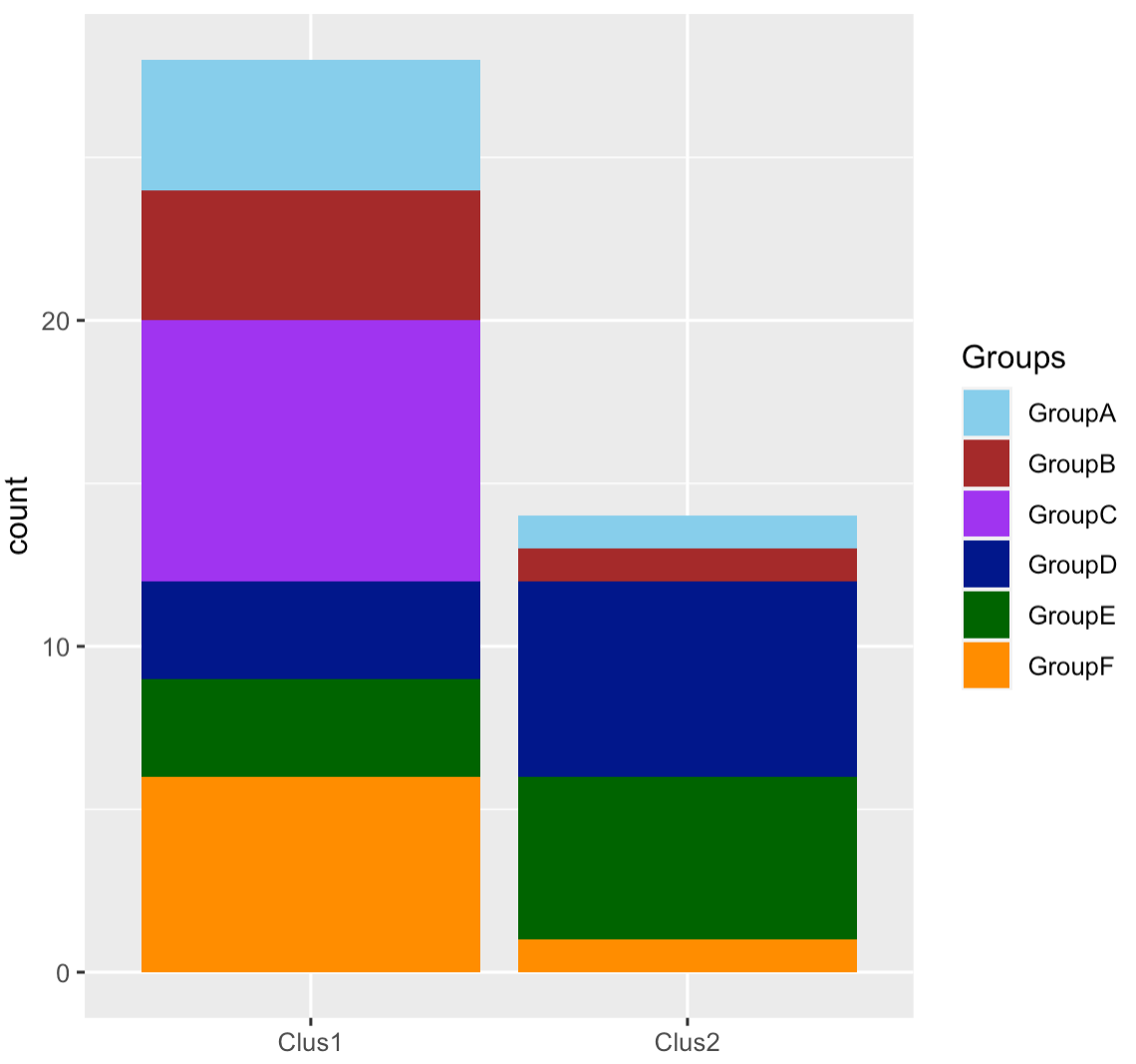
- 如何在数字上添加Clus1和Clus2中每个组的示例号?
、
- 、GroupE和GroupF都可以在Clus1和Clsu2中看到。那么,如何检查他们的交往呢?有这样的例子吗?
回答 1
Stack Overflow用户
发布于 2020-11-21 11:57:51
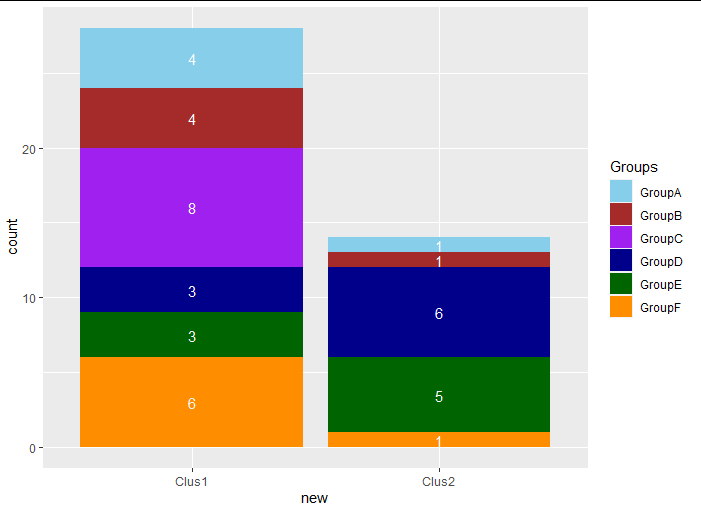
您可以添加如下示例编号:
ggplot(df,aes(x = new,fill = Groups)) +
geom_bar() +
geom_text(stat = "count", aes(label = ..count..), color = "white",
position = position_stack(vjust = 0.5)) +
scale_fill_manual(values=group.colors)
第二个问题还不是很清楚,但是你可以用Fisher的精确测试来检查E和F在这两个集群中的比例是否有很大的不同--也许这就是你的意思?
fisher.test(with(df[df$Groups %in% c("GroupE", "GroupF"),], table(Groups, new)))
#>
#> Fisher's Exact Test for Count Data
#>
#> data: with(df[df$Groups %in% c("GroupE", "GroupF"), ], table(Groups, new))
#> p-value = 0.1189
#> alternative hypothesis: true odds ratio is not equal to 1
#> 95 percent confidence interval:
#> 0.001827082 1.768053629
#> sample estimates:
#> odds ratio
#> 0.1189474 页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64942670
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号