
如何获取使用美汤的会员名单
如何获取使用美汤的会员名单
提问于 2020-11-22 14:17:43
我试过这样做
URL=str(browser.current_url)
page=requests.get(URL)
soup = BeautifulSoup(page.content, "html.parser")
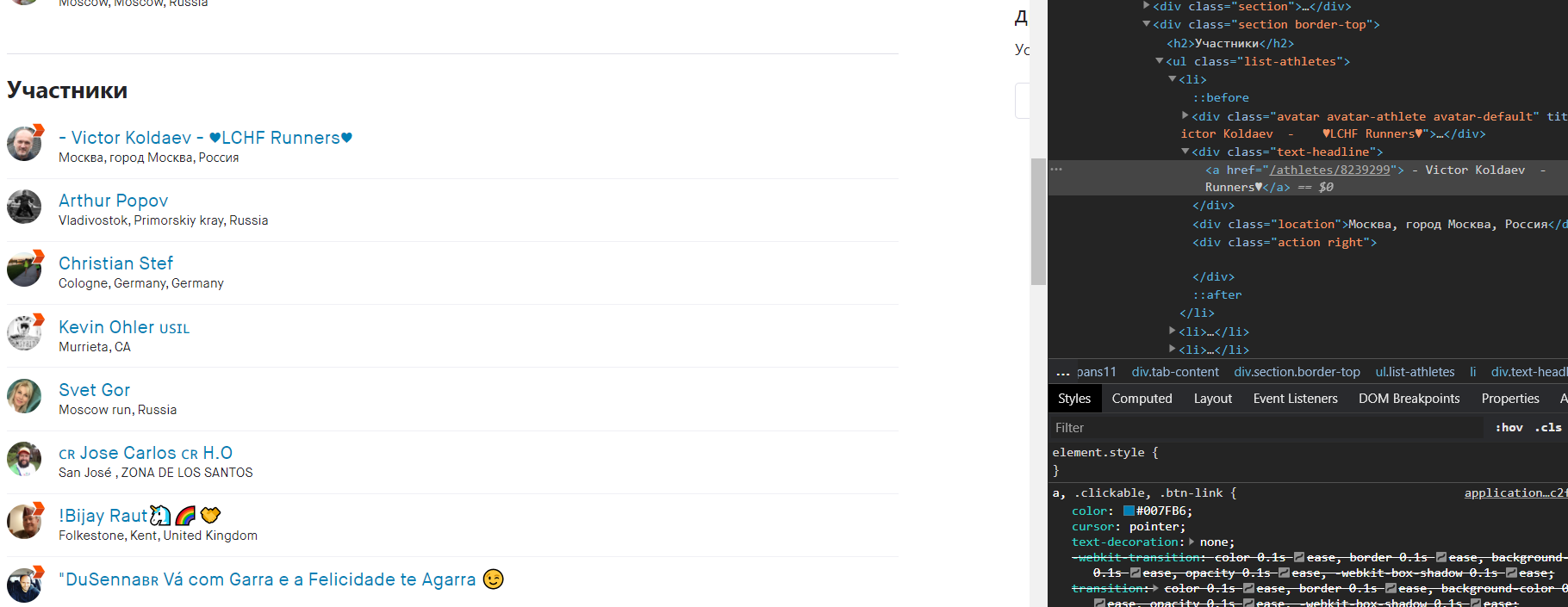
imena = soup.findAll('a', class_='text-headline')
imena回答 2
Stack Overflow用户
回答已采纳
发布于 2020-11-22 15:46:21
假设URL是斯塔瓦俱乐部Россия2021的Members选项卡,也就是说,https://www.strava.com/clubs/236545/members应该可以让所有成员跨越193个页面(您确实应该使用Strava API.):
import time
from bs4 import BeautifulSoup
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
BASE_URL = "https://www.strava.com/clubs/236545/members?page="
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get(f"{BASE_URL}{1}")
driver.find_element_by_id("email").send_keys("<your-email>")
driver.find_element_by_id("password").send_keys("<your-password>")
driver.find_element_by_id("login-button").click()
time.sleep(1)
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
num_pages = int(soup.find("ul", "pagination").find_all("li")[-2].text)
# Ignore the admins shown on each page
athletes = soup.find_all("ul", {"class": "list-athletes"})[1]
members = [
avatar.attrs['title']
for avatar in athletes.find_all("div", {"class": "avatar"})
if 'title' in avatar.attrs
]
for page in range(2, num_pages + 1):
time.sleep(1)
driver.get(f"{BASE_URL}{page}")
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
athletes = soup.find_all("ul", {"class": "list-athletes"})[1]
for avatar in athletes.find_all("div", {"class": "avatar"}):
if 'title' in avatar.attrs:
members.append(avatar.attrs['title'])
# Print first 10 members
print('\n'.join(m.strip() for m in members[:10]))
driver.close()输出(前10个成员):
- Victor Koldaev - ♥LCHF Runners♥
Antonio Raposo ®️
Vadim Issin
"DuSenna Vá com Garra e a Felicidade te Agarra
#MIX MIX
#RunВасяRun ...
$ерЖ КЛИМoff
'Luis Fernando Osorio' MTB
( CE )Faisal ALShammary "حائل $الشرقية "
(# Monique #) bermudezStack Overflow用户
发布于 2020-11-22 15:03:36
您需要首先获得“文本标题”元素div,然后循环遍历每个元素以获得锚链接。
URL=str(browser.current_url)
page=requests.get(URL)
soup = BeautifulSoup(page.content, "html.parser")
members = soup.findAll('div', {'class': 'text-headline'})
for (member in members):
name = member.find("a")
print(name.get_text())页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64955223
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号