
数据流
我有python数据流作业,它从pubsub读取数据,提取一些用户信息,将它们窗口设置为5分钟的时间框架,不同,然后进行更多的处理。
with beam.Pipeline(options=pipeline_options) as p:
users = (p
| "ReadEvents" >> beam.io.ReadFromPubSub(subscription=known_args.subscription, with_attributes=False)
| "ExtractUsers" >> beam.ParDo(ExtractUserIdHash())
| beam.ParDo(AddTimestampFn())
| beam.WindowInto(beam.window.FixedWindows(300, 0), allowed_lateness=Duration(seconds=3*24*60*60))
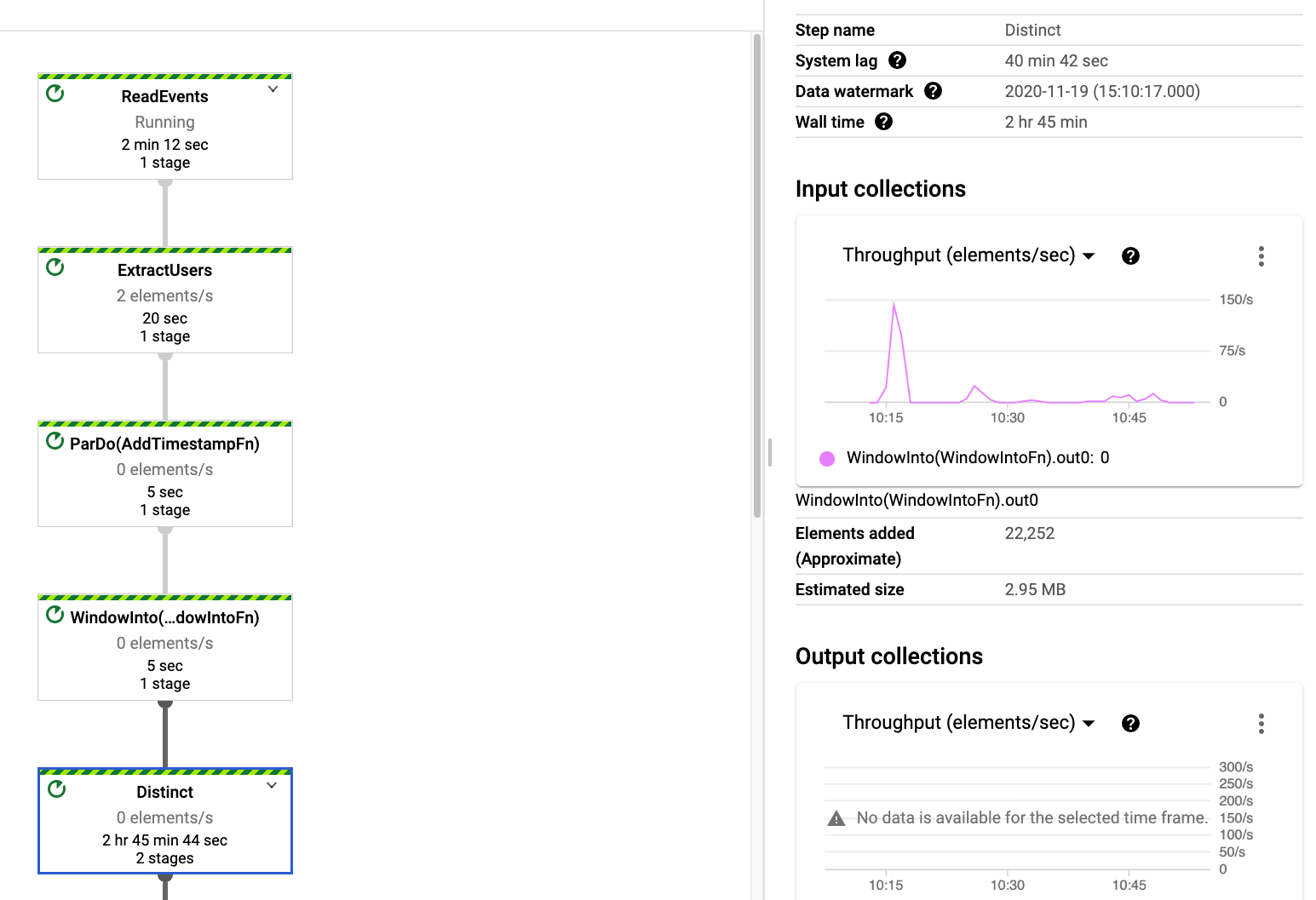
| beam.Distinct())这在开发环境中很好,在pubsub中有大约5000个元素,但是当我将它部署到生产环境中时,它就被卡住了。看一下图表(下面的截图),看起来
Distinct花了很长时间- 吞吐量仍然很低
从CPU利用率来看,似乎创建了大量的工作人员,并且使用了大量CPU(并且由于某种原因重新创建了CPU)。
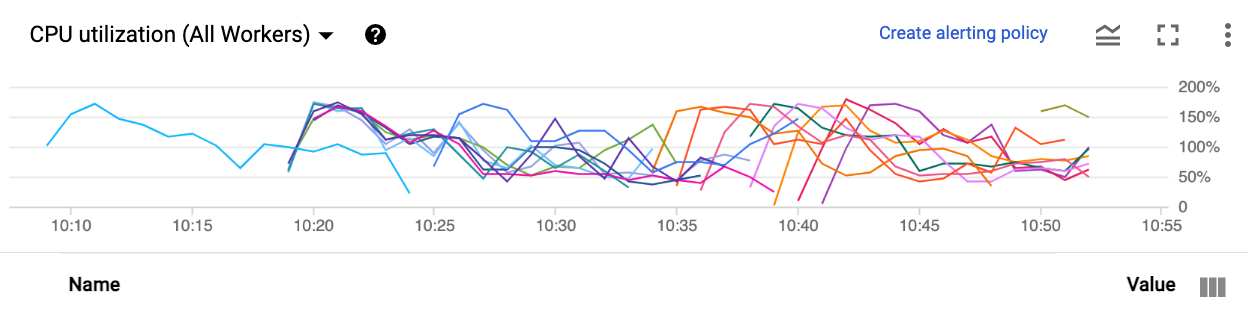
我的问题是:( A) Distinct中似乎只有3MB的数据。为什么要花这么长时间来处理和使用这么多CPU?( B)为什么输入吞吐量这么低?即使Distinct速度慢,我也能以某种方式指示数据流读取更多的数据,这样我们才能赶上积压吗?
编辑:以下是我使用的一些可能相关的标志
--worker_machine_type e2-medium \
--max_num_workers 10 \回答 2
Stack Overflow用户
发布于 2020-11-22 21:09:46
结果显示,工作者正在耗尽磁盘空间,并自行重新启动。我的ParDo安装文件(ML模型)大小约为50 My。似乎数据流VM使用Docker来运行多个工作人员,并且新的工作人员被连续地重新创建(我从docker中观察到)。
当我将ssh转换为工作者时,使用
gcloud compute ssh --zone us-east1-c <name of VM like myjob-abc-harness-abc>并做到了
# list of containers
docker ps --no-trunc
# sudo tail -f /var/lib/docker/containers/<container_id>/<container_id>-json.log我看到了很多像no space left on device这样的日志
我再次尝试使用disk_size_gb参数https://cloud.google.com/dataflow/docs/guides/specifying-exec-params#setting-other-cloud-dataflow-pipeline-options运行作业。
我指定了250 it(在我的情况下,它似乎是默认的),然后作业开始工作一个小时,然后又开始失败。我还试图编写临时文件夹tempfile.gettempdir(),但我猜当容器停止时tmp文件没有被清除,所以没有帮助。
Stack Overflow用户
发布于 2020-11-25 07:05:53
https://stackoverflow.com/questions/64951482
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号