
EasyOCR不识别单数
我正在尝试分析视频中的页脚并检索当前的页码。我让框架集合正常工作,但是我很难用EasyOCR读取页面编号本身。
我已经试过使用pytesseract,但效果不太好。我误解了数字: 10被识别为113,6被识别为41,等等。总的来说,它非常不一致,即使我用灰度、阈值和裁剪(只分析页脚的分页数区域)正确地格式化输入图像。
以下是代码:
def getPageNumberTest(path, psm):
image = cv2.imread(path)
height = len(image)
width = len(image[0])
# the height of the footer
footerHeight = 90 # int(height / 15.5)
# retrieve only the footer from the image
cropped = image[height-footerHeight:height,0:width]
results = reader.readtext(cropped)这给了我以下输出:

我错过了什么环境吗?有没有一种方法可以指示EasyOCR只查找数字?任何帮助或提示都是非常感谢的!
编辑:
在对数字图像进行了一些优化之后,我现在又回到了最初的阶段,根本没有优化图像。剩下的就是转换为灰度和调整大小。
这是正常输入的样子:

但结果是:
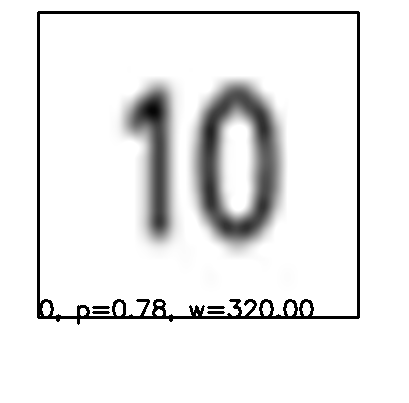
这很奇怪,因为对于大多数数字(特别是个位数)来说,这是完美无缺的,产生了95%以上的确定性。
我试过去模糊,阈值,去噪用cv2.过滤器2D(),模糊,.
例如,当我使用阈值处理时,我的输出看起来如下(忽略"1",对于单数“1”同样适用):
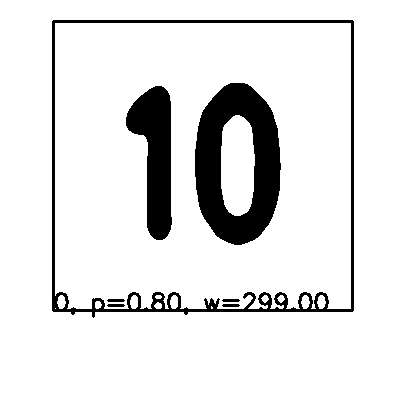
我看过模式匹配,这不是一种选择,因为我事先不知道页码的形状.
回答 2
Stack Overflow用户
发布于 2022-01-04 06:46:26
txt = pytesseract.image_to_string(final_image, config='--psm 13 --oem 3 -c tessedit_char_whitelist=0123456789')Stack Overflow用户
发布于 2022-08-16 12:35:31
根据我的测试,在大多数场景中,PaddleOCR比easyOCR工作得更好。
https://stackoverflow.com/questions/65196162
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号