
为什么softmax分类器梯度除以批处理大小(CS231n)?
为什么softmax分类器梯度除以批处理大小(CS231n)?
提问于 2020-12-13 12:20:03
问题
CS231 用反向传播法计算解析梯度首先实现了一种软件最大分类器,其梯度从(softmax + log损失)除以批次大小(用于前向成本计算的数据数和训练中的反向传播)。
请帮助我理解为什么它需要除以批大小。

得到梯度的链式规则应该在下面。我应该在哪里合并这个部门?
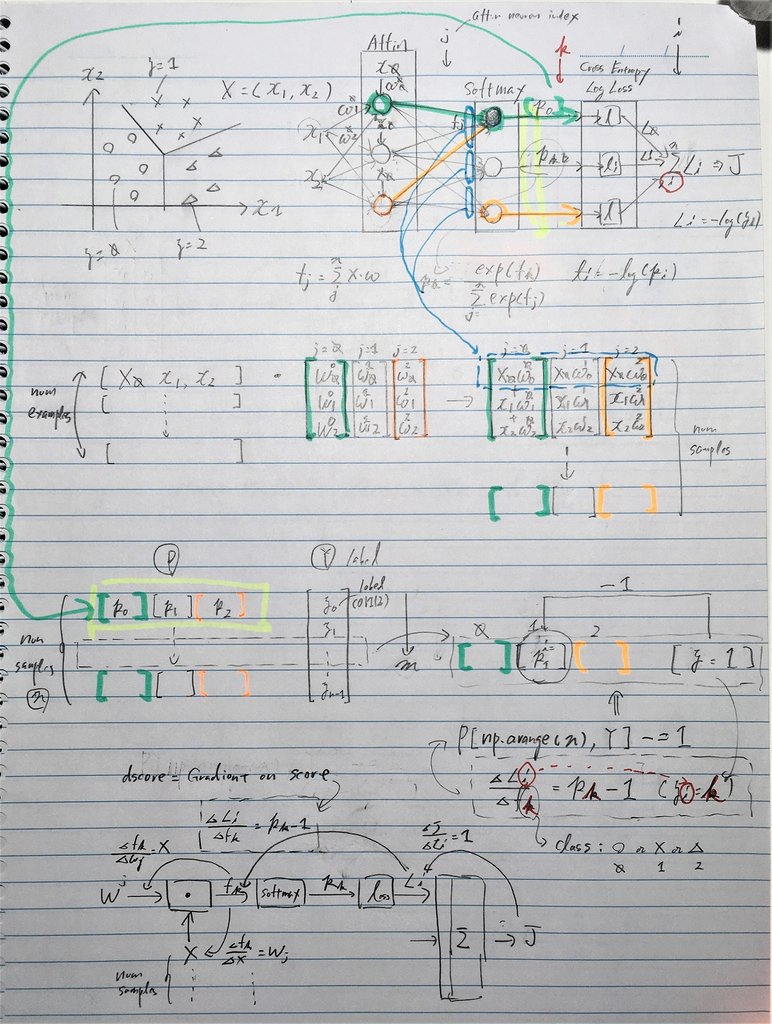
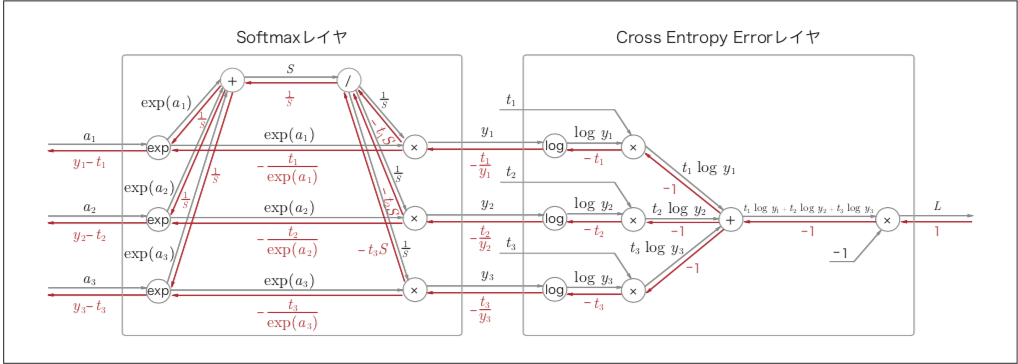
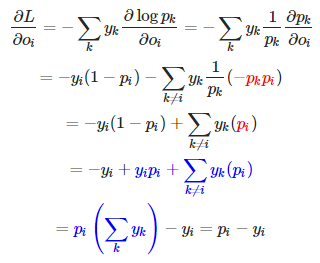
代码
N = 100 # number of points per class
D = 2 # dimensionality
K = 3 # number of classes
X = np.zeros((N*K,D)) # data matrix (each row = single example)
y = np.zeros(N*K, dtype='uint8') # class labels
#Train a Linear Classifier
# initialize parameters randomly
W = 0.01 * np.random.randn(D,K)
b = np.zeros((1,K))
# some hyperparameters
step_size = 1e-0
reg = 1e-3 # regularization strength
# gradient descent loop
num_examples = X.shape[0]
for i in range(200):
# evaluate class scores, [N x K]
scores = np.dot(X, W) + b
# compute the class probabilities
exp_scores = np.exp(scores)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K]
# compute the loss: average cross-entropy loss and regularization
correct_logprobs = -np.log(probs[range(num_examples),y])
data_loss = np.sum(correct_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(W*W)
loss = data_loss + reg_loss
if i % 10 == 0:
print "iteration %d: loss %f" % (i, loss)
# compute the gradient on scores
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples # <---------------------- Why?
# backpropate the gradient to the parameters (W,b)
dW = np.dot(X.T, dscores)
db = np.sum(dscores, axis=0, keepdims=True)
dW += reg*W # regularization gradient
# perform a parameter update
W += -step_size * dW
b += -step_size * db回答 1
Stack Overflow用户
发布于 2020-12-13 15:03:57
这是因为你在平均梯度,而不是直接取所有梯度的总和。
当然,你不能以这个大小来划分,但是这个部门有很多优势。主要原因是这是一种正规化(以避免过度适应)。在梯度较小的情况下,重量不能超出比例。
这种归一化允许在不同的实验中比较不同的批大小配置(如果两个批处理的性能取决于批大小,如何比较它们?)
如果将梯度和除以此大小,则可以使用更高的学习率来提高培训的速度。
这个答案在交叉验证的社区中非常有用。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65275522
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号