
Python请求模块被卡在requests.get()上,并被超时
Python请求模块被卡在requests.get()上,并被超时
提问于 2020-12-16 06:04:37
我一直在尝试从以下网站上搜索:"https://www.india.ford.com/cars/aspire/“
import requests
from bs4 import BeautifulSoup
import csv
response = requests.get("https://www.india.ford.com/cars/aspire/", timeout=5)
if response.status_code!=200:
print("error!")
else:
print(response.status_code)死刑被无限期地拖延了。
浅谈timeout=5的使用
我得到以下错误:
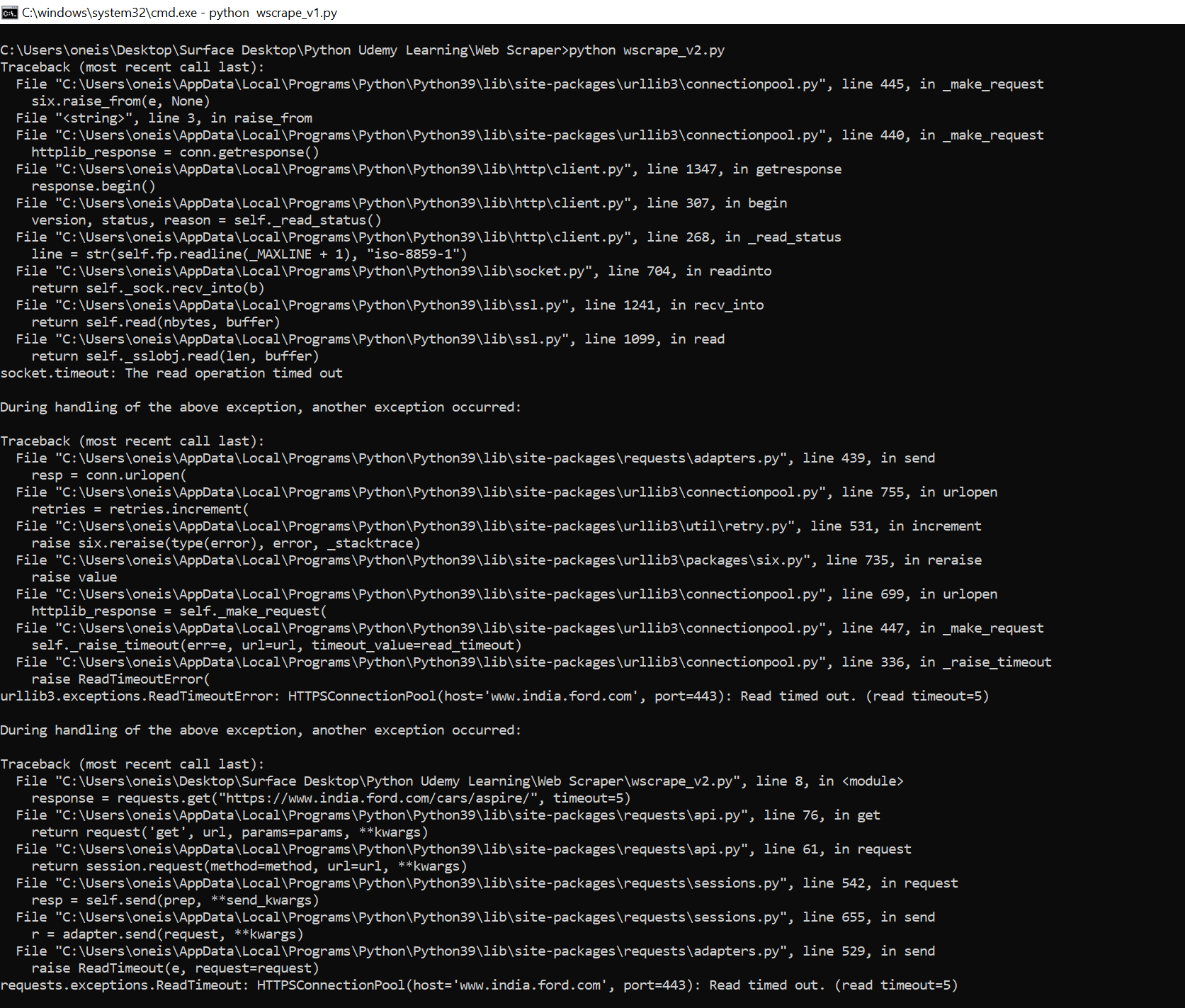
我是新手,抱歉,如果这是个问题的话。任何帮助都是非常感谢的!
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-12-16 06:12:39
超时需要使用试除。
此页面需要伪装浏览器。
try:
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36',
}
response = requests.get("https://www.india.ford.com/cars/aspire/", headers=headers, timeout=5)
if response.status_code != 200:
print("error!")
else:
print(response.status_code)
except requests.exceptions.Timeout as error:
print('time out')页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65318082
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号