
向海运条添加标签
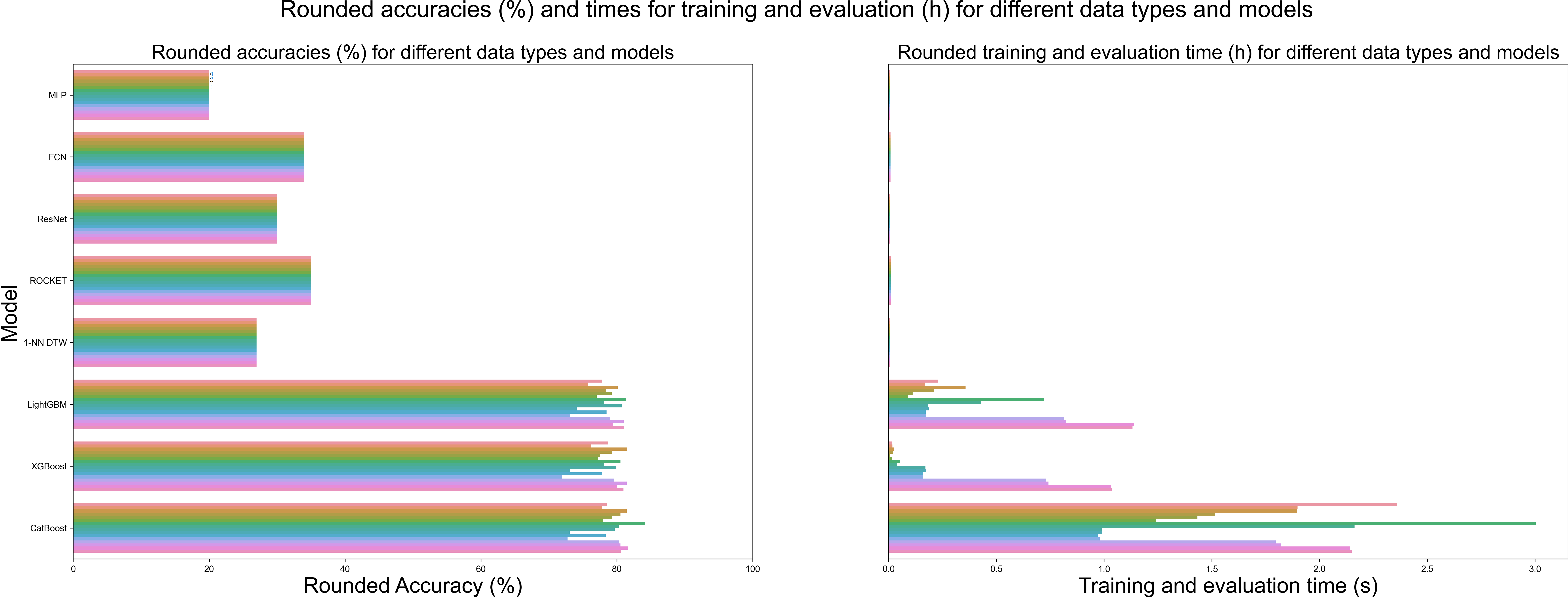
我试图创建两个垂直对齐的水平分组条形图。我有大量的数据为几个机器学习模型及其相应的运行时,并希望以一种有意义的方式显示所有这些数据。到目前为止,我的尝试如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
labels = ['MLP','FCN','ResNet','ROCKET','1-NN DTW','LightGBM','XGBoost','CatBoost']
Data1_Accuracy = [20, 34, 30, 35, 27,77.83125,78.7204167,78.5354167]
Data2_Accuracy = [20, 34, 30, 35, 27,75.7979167,76.2520833,77.87]
Data3_Accuracy = [20, 34, 30, 35, 27,80.14625,81.5033333,81.4625]
Data4_Accuracy = [20, 34, 30, 35, 27,78.3841667,79.34875,80.5270833]
Data5_Accuracy = [20, 34, 30, 35, 27,79.2495833,77.5370833,79.2666667]
Data6_Accuracy = [20, 34, 30, 35, 27,77.03125,77.2429167,77.9960275]
Data7_Accuracy = [20, 34, 30, 35, 27,81.3241667,80.5408333,84.2083333]
Data8_Accuracy = [20, 34, 30, 35, 27,78.1470833,78.1225,80.2754167]
Data9_Accuracy = [20, 34, 30, 35, 27,80.7383333,79.9358333,79.6916667]
Data10_Accuracy = [20, 34, 30, 35, 27,74.1095833,73.0879167,73.0529167]
Data11_Accuracy = [20, 34, 30, 35, 27,78.4775,77.8658333,78.35]
Data12_Accuracy = [20, 34, 30, 35, 27,73.0991667,71.9683333,72.75625]
Data13_Accuracy = [20, 34, 30, 35, 27,79.03,79.575,80.3870833]
Data14_Accuracy = [20, 34, 30, 35, 27,81.0241667,81.455,80.5516667]
Data15_Accuracy = [20, 34, 30, 35, 27,79.4829167,80.01375,81.68]
Data16_Accuracy = [20, 34, 30, 35, 27,81.1158333,80.9795833,80.6541667]
Data1_Times = [20, 34, 30, 35, 27,829.0177925,58.6558111,8493.968922]
Data2_Times = [20, 34, 30, 35, 27,604.5935536,64.3871907,6833.585728]
Data3_Times = [20, 34, 30, 35, 27,1286.01507,92.4329714,6821.308612]
Data4_Times = [20, 34, 30, 35, 27,757.3903304,78.7253731,5455.483287]
Data5_Times = [20, 34, 30, 35, 27,401.3722335,30.4119882,5160.041989]
Data6_Times = [20, 34, 30, 35, 27,321.4673242,54.1971346,4465.557807]
Data7_Times = [20, 34, 30, 35, 27,2598.48826,193.1256487,10811.65574]
Data8_Times = [20, 34, 30, 35, 27,1545.059628,139.9638344,7784.332016]
Data9_Times = [20, 34, 30, 35, 27,663.416329,615.3660963,3560.337827]
Data10_Times = [20, 34, 30, 35, 27,670.1615828,621.8249994,3567.653313]
Data11_Times = [20, 34, 30, 35, 27,619.1959161,572.3292757,3493.582855]
Data12_Times = [20, 34, 30, 35, 27,626.107683,579.0746278,3528.605614]
Data13_Times = [20, 34, 30, 35, 27,2936.5633,2631.284413,6465.254111]
Data14_Times = [20, 34, 30, 35, 27,2967.02757,2672.068268,6551.57865]
Data15_Times = [20, 34, 30, 35, 27,4102.511475,3711.899848,7704.401239]
Data16_Times = [20, 34, 30, 35, 27,4075.485739,3726.896591,7737.482708]
Data1_TimesInHours = np.array(Data1_Times) / 3600
Data2_TimesInHours = np.array(Data2_Times) / 3600
Data3_TimesInHours = np.array(Data3_Times) / 3600
Data4_TimesInHours = np.array(Data4_Times) / 3600
Data5_TimesInHours = np.array(Data5_Times) / 3600
Data6_TimesInHours = np.array(Data6_Times) / 3600
Data7_TimesInHours = np.array(Data7_Times) / 3600
Data8_TimesInHours = np.array(Data8_Times) / 3600
Data9_TimesInHours = np.array(Data9_Times) / 3600
Data10_TimesInHours = np.array(Data10_Times) / 3600
Data11_TimesInHours = np.array(Data11_Times) / 3600
Data12_TimesInHours = np.array(Data12_Times) / 3600
Data13_TimesInHours = np.array(Data13_Times) / 3600
Data14_TimesInHours = np.array(Data14_Times) / 3600
Data15_TimesInHours = np.array(Data15_Times) / 3600
Data16_TimesInHours = np.array(Data16_Times) / 3600
accuraciesDataFrame = pd.DataFrame({'Index': labels,
'Data1_Accuracy': Data1_Accuracy,
'Data2_Accuracy': Data2_Accuracy,
'Data3_Accuracy': Data3_Accuracy,
'Data4_Accuracy': Data4_Accuracy,
'Data5_Accuracy': Data5_Accuracy,
'Data6_Accuracy': Data6_Accuracy,
'Data7_Accuracy': Data7_Accuracy,
'Data8_Accuracy': Data8_Accuracy,
'Data9_Accuracy': Data9_Accuracy,
'Data10_Accuracy': Data10_Accuracy,
'Data11_Accuracy': Data11_Accuracy,
'Data12_Accuracy)': Data12_Accuracy,
'Data13_Accuracy': Data13_Accuracy,
'Data14_Accuracy': Data14_Accuracy,
'Data15_Accuracy': Data15_Accuracy,
'Data16_Accuracy': Data16_Accuracy},
columns = ['Index','Data1_Accuracy','Data2_Accuracy','Data3_Accuracy','Data4_Accuracy','Data5_Accuracy','Data6_Accuracy','Data7_Accuracy','Data8_Accuracy','Data9_Accuracy','Data10_Accuracy',
'Data11_Accuracy','Data12_Accuracy','Data13_Accuracy','Data14_Accuracy','Data15_Accuracy','Data16_Accuracy'])
timesDataFrame = pd.DataFrame({'Index': labels,
'Data1_TimesInHours': Data1_TimesInHours,
'Data2_TimesInHours': Data2_TimesInHours,
'Data3_TimesInHours': Data3_TimesInHours,
'Data4_TimesInHours': Data4_TimesInHours,
'Data5_TimesInHours': Data5_TimesInHours,
'Data6_TimesInHours': Data6_TimesInHours,
'Data7_TimesInHours': Data7_TimesInHours,
'Data8_TimesInHours': Data8_TimesInHours,
'Data9_TimesInHours': Data9_TimesInHours,
'Data10_TimesInHours': Data10_TimesInHours,
'Data11_TimesInHours': Data11_TimesInHours,
'Data12_TimesInHours': Data12_TimesInHours,
'Data13_TimesInHours': Data13_TimesInHours,
'Data14_TimesInHours': Data14_TimesInHours,
'Data15_TimesInHours': Data15_TimesInHours,
'Data16_TimesInHours': Data16_TimesInHours},
columns = [
'Index','Data1_TimesInHours','Data2_TimesInHours','Data3_TimesInHours','Data4_TimesInHours',
'Data5_TimesInHours','Data6_TimesInHours','Data7_TimesInHours','Data8_TimesInHours','Data9_TimesInHours','Data10_TimesInHours',
'Data11_TimesInHours','Data12_TimesInHours','Data13_TimesInHours','Data14_TimesInHours','Data15_TimesInHours','Data16_TimesInHours'
])
accuraciesDataFrameMelted = pd.melt(accuraciesDataFrame, id_vars=['Index'])
timesDataFrameMelted = pd.melt(timesDataFrame, id_vars=['Index'])
fig, axs = plt.subplots(1,2)
fig.set_size_inches(30,10)
xRangeFirstChart = list(range(0,101))
fig.suptitle('Rounded accuracies (%) and times for training and evaluation (h) for different data types and models',fontsize=26)
g1 = sns.barplot(x='value', y='Index', hue='variable', data=accuraciesDataFrameMelted, ax=axs[0])
axs[0].set_xlim([xRangeFirstChart[0],xRangeFirstChart[-1]])
axs[0].set_ylabel('Model',fontsize=24)
axs[0].set_xlabel('Rounded Accuracy (%)',fontsize=24)
axs[0].set_title('Rounded accuracies (%) for different data types and models',fontsize=22)
g2 = sns.barplot(x='value', y='Index', hue='variable', data=timesDataFrameMelted, ax=axs[1])
axs[0].get_legend().remove()
axs[1].get_legend().remove()
axs[1].get_yaxis().set_visible(False)
axs[1].set_xlabel('Training and evaluation time (h)',fontsize=24)
axs[1].set_title('Rounded training and evaluation time (h) for different data types and models',fontsize=22)
plt.savefig('PathToFigure/MyFigure.png', dpi=300, bbox_inches='tight', pad_inches=0)我所缺少的是一种在每一栏中写标签“数据1”、“数据2”、“数据3”等的方法。请参考图片来显示我正在努力实现的目标。任何帮助都是非常感谢的!
回答 1
Stack Overflow用户
发布于 2020-12-16 23:53:07
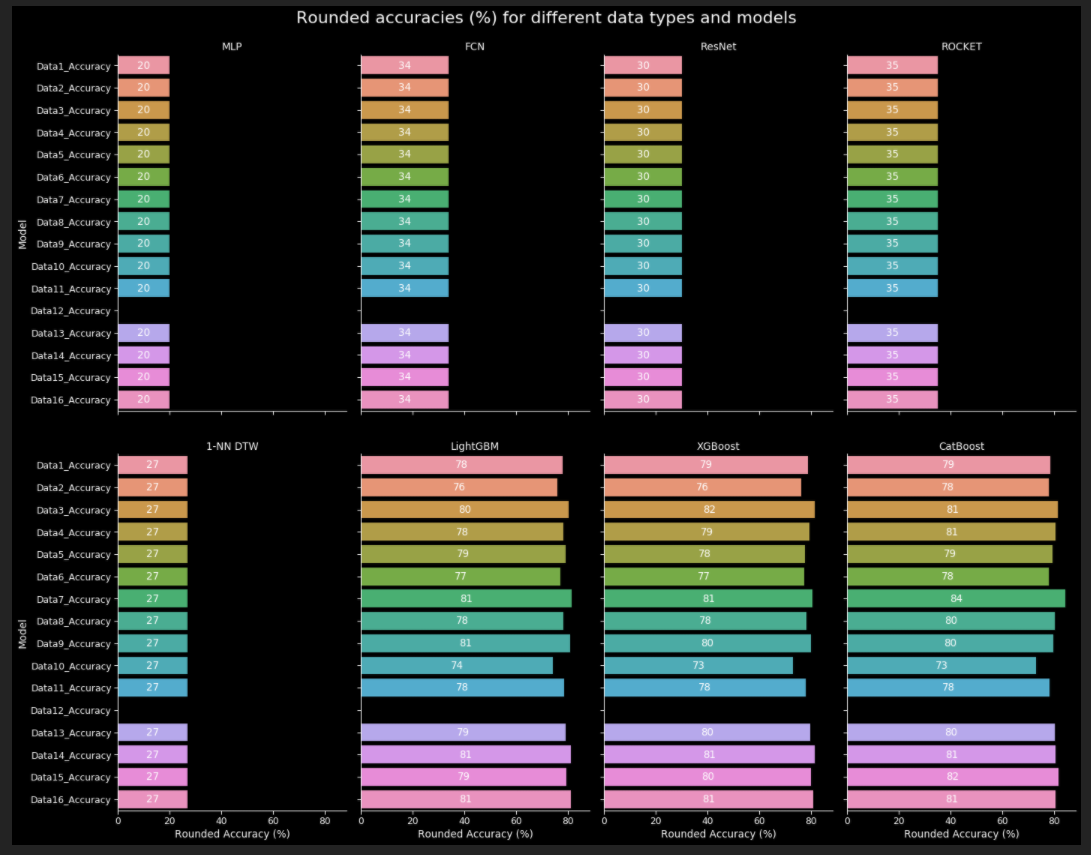
由于一个图中有这么多的条,所以I would use sns.catplot可以将不同的类别绘制到一个面网格中,然后添加标签就更好了,您可以使用自定义函数add_labels (请注意不同的参数--请随意删除一些/添加其他参数)。I have adapted from this solution)。
如果在创建连环图时传递sharex=False (请参阅此解决方案的结尾),则还可以使x轴更加可变。
此外,sns.catplot在添加子图时也不能很好地工作,因此您可以将其保存为一个图形。这就是为什么我使用plt.close(fig)来消除我们创建的空白图形的原因,这也意味着向该图形添加任何格式(例如添加一个标题)都是毫无意义的,因为我们最终要删除该图形;然而,也存在一些黑客。一种方法是将数据保存为单独的数字,并使用here的解决方案:将其组合成一个.pdf。我认为最好有额外的空间,每页一张图或图像。Another option is to use somewhat of a hack to get into one figure:
fig, ax = plt.subplots(nrows=2)
sns.set_context('paper', font_scale=1.4)
plt.style.use('dark_background')
n_cols=4 #this is used later in a couple of places to make dynamic
g1 = sns.catplot(data=accuraciesDataFrameMelted, x='value', y='variable', col='Index', kind='bar',
col_wrap=n_cols, ax=ax[0])
g1.fig.suptitle('Rounded accuracies (%) for different data types and models',fontsize=22)
plt.subplots_adjust(top=0.9, bottom=-0.5)
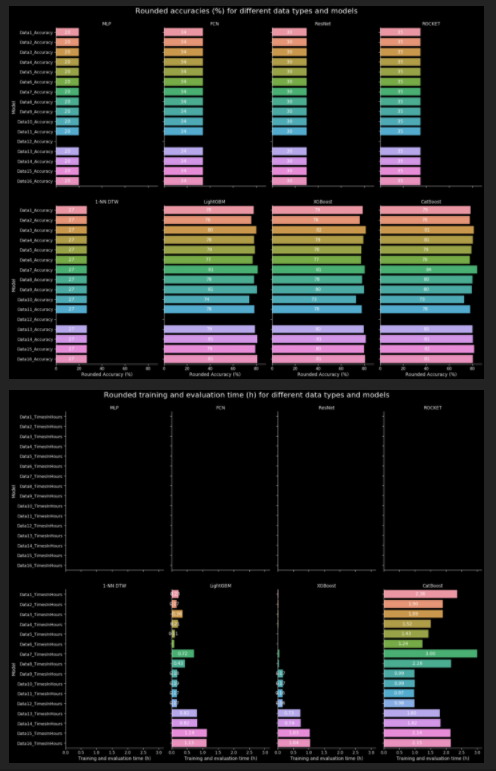
g2 = sns.catplot(data=timesDataFrameMelted, x='value', y='variable', col='Index', kind='bar',
col_wrap=n_cols, ax=ax[1])
g2.fig.suptitle('Rounded training and evaluation time (h) for different data types and models',fontsize=22)
plt.subplots_adjust(top=0.9, bottom=-0.5)
def add_labels(graph, category_size, axis_number, omit_thresh, width_var, num_format):
for i in range(category_size):
ax = graph.facet_axis(axis_number,i)
for p in ax.patches:
if p.get_width() > omit_thresh: # omit labels close to zero or other threshold
width = p.get_width() * width_var # get bar length
ax.text(width, # set the text at 1 unit right of the bar
p.get_y() + p.get_height() / 2, # get Y coordinate + X coordinate / 2
num_format.format(p.get_width()), # set variable to display, 2 decimals
ha = 'center', # horizontal alignment
va = 'center') # vertical alignment
else:
pass
l1 = len(accuraciesDataFrameMelted['Index'].unique())
l2 = len(timesDataFrame['Index'].unique())
add_labels(graph=g1, category_size=l1, axis_number=0, omit_thresh=1, width_var=0.5, num_format='{:1.0f}')
add_labels(graph=g2, category_size=l2, axis_number=1, omit_thresh=0.1, width_var=0.5, num_format='{:1.2f}')
for g, i in zip([g1,g2], [0, n_cols]):
g.axes[i].set_ylabel('Model')
for g in [g1,g2]:
g.set_titles("{col_name}", fontsize=12)
g1.set_axis_labels(x_var="Rounded Accuracy (%)", y_var="Model")
g2.set_axis_labels(x_var="Training and evaluation time (h)", y_var="Model")
plt.close(fig)
g1.fig.savefig('g1.pdf',dpi=300, bbox_inches = "tight")
g2.fig.savefig('g2.pdf',dpi=300, bbox_inches = "tight")
plt.show()(放大以显示第一张图)
(放大以显示这两幅图)
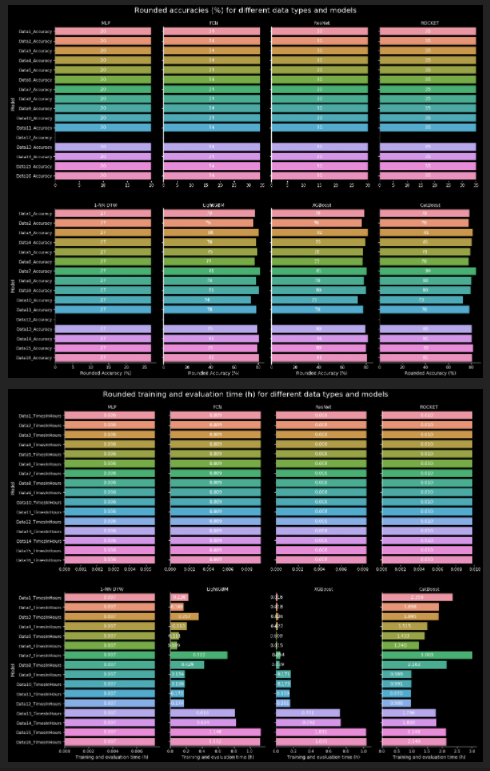
如果在创建sharex=False时传递catplot,还可以通过以下更改(传递sharex并将函数中的一个参数更改为`omit_thresh=0)使x轴更加可变:
g1 = sns.catplot(data=accuraciesDataFrameMelted, x='value', y='variable',
col='Index', kind='bar',
col_wrap=n_cols, ax=ax[0], sharex=False)
g2 = sns.catplot(data=timesDataFrameMelted, x='value', y='variable', col='Index', kind='bar',
col_wrap=n_cols, ax=ax[1], sharex=False)
add_labels(graph=g1, category_size=l1, axis_number=0, omit_thresh=0, width_var=0.5, num_format='{:1.0f}')
add_labels(graph=g2, category_size=l2, axis_number=1, omit_thresh=0, width_var=0.5, num_format='{:1.3f}')
https://stackoverflow.com/questions/65329934
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号