
为什么这个图像上的英语单词不能识别?
为什么这个图像上的英语单词不能识别?
提问于 2020-12-25 03:31:34
我使用tesseract 4.0来识别英语单词,但是在这个图像上失败只识别,没有任何单词被识别,
任何人都可以给小费,谢谢
r=pytesseract.image_to_string('6.jpg', lang='eng')
print(r){kind=link}
更新:
我试着用在线网站进行OCR。
而且很管用,但为什么?
我怎么才能用tesseract来识别它呢?
回答 1
Stack Overflow用户
发布于 2020-12-25 05:25:55
问题是pytesseract不是旋转不变的.因此,您需要做额外的预处理.来源
- 我的第一个想法是用一个小角度旋转图像。
- img = imutils.rotate_bound(cv2.imread("YD90o.png"),4)
- 结果:
- 
- 如果我申请
adaptive-threshold
- 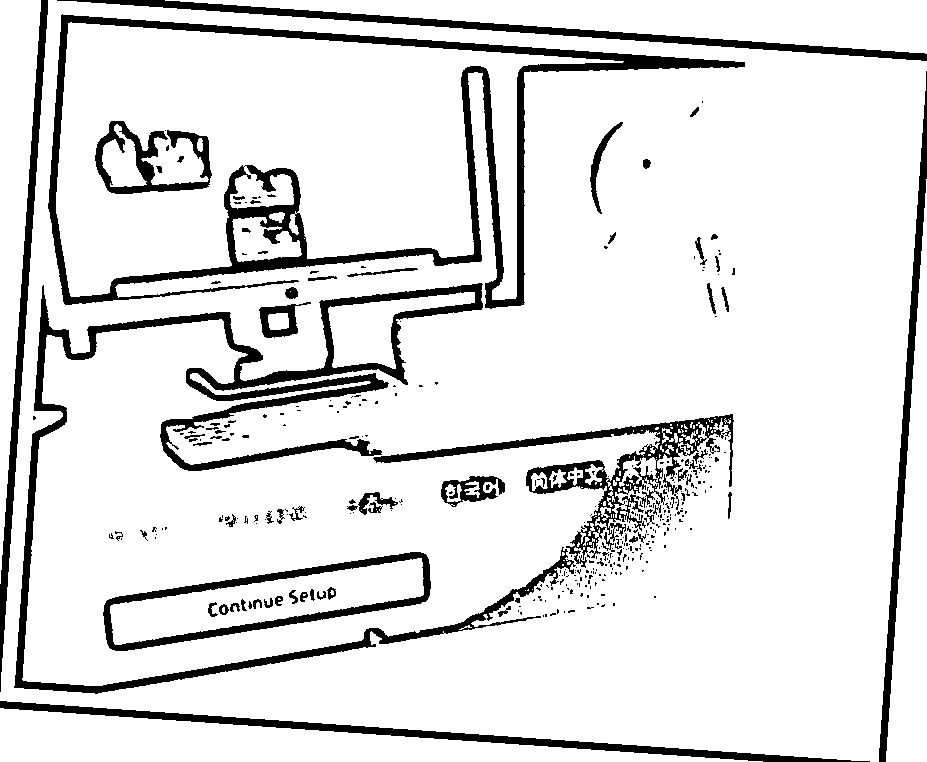
- 要使用
pytesseract阅读,您需要设置其他配置:
- pytesseract.image\_to\_string(thr, lang="eng", config="--psm 6")- PSM (page-segmentation-mode) 6 is Assume a single uniform block of text. [source](https://stackoverflow.com/questions/44619077/pytesseract-ocr-multiple-config-options)- 结果:
- You want to get the last sentence of the image.- txt = pytesseract.image\_to\_string(thr, lang="eng", config="--psm 6") txt = txt.replace('\f', '').split('\n') print(txt[len(txt)-2])- Result:- Continue Setub ie Gene网站可能会使用深度学习的方法来检测图像中的单词。但是,当我使用newocr.com时,结果是:
oy Eee a
setuP me -
continve ae页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65445043
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号