
如何将字符串列表拆分为一行/单元格中的几行?
如何将字符串列表拆分为一行/单元格中的几行?
提问于 2021-01-01 22:41:36
在由Python从CSV文件导入的dataframe单元格中,我有一个字符串'A‘、'B’、'C‘(与下面的(第1行,ColA)完全相同)。
现在我想让它像(第2行,ColA)在熊猫的数据,如下面上传的图片,我如何实现它?当我使用to_CSV将它保存到CSV时,我还希望它在excel中看起来像这样。
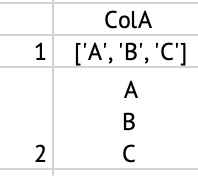
输入:
df = pd.DataFrame({'ColA' : "['A','B','C']"}, index=[1])输出:
ColA
1 ['A','B','C']
2 A
B
C我认为text.explode不是一个解决方案,因为它将列表分成几行。谢谢!祝你们新年健康平安!
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-01-01 23:04:30
您必须使用replace进行一些清理。对于replace,在字符串中有两个不同的模式,我需要两个单独的替换。其中一个替代品是'\n',所以当发送到excel时,我可以在新的行上看到。另一个替换是用空字符串替换,即nothing。or运算符|为''的空字符串输出分离不同可能的替换。[和]是regex字符,所以您必须用\来转义,所以基本上是要去掉[、]和'。还必须将regex=True传递给replace。
df = pd.DataFrame({'ColA' : "['A','B','C']"}, index=[1])
df['ColA'] = df['ColA'].replace(["','", "\[|\]|'"], ['\n', ''], regex=True)
df
Out[1]:
ColA
1 A\nB\nC并在扩展行宽后在Excel中输出:

页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65534341
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号