
使用mle2函数
我想在这样的模型中找到参数epsilon和mu的MLE:
\frac{1}{mu1}e^{-x/mu1}+\frac{1}{mu2}e^[-x/mu2}$$ \sim $$X
library(Renext)
library(bbmle)
epsilon = 0.01
#the real model
X <- rmixexp2(n = 20, prob1 = epsilon, rate1 = 1/mu1, rate2 = 1/mu2)
LL <- function(mu1,mu2, eps){
R = (1-eps)*dexp(X,rate=1/mu1,log=TRUE)+eps*dexp(X,rate=1/mu2,log=TRUE)
-sum(R)
}
fit_norm <- mle2(LL, start = list(eps = 0,mu1=1, mu2 = 1), lower = c(-Inf, 0),
upper = c(Inf, Inf), method = 'L-BFGS-B')
summary(fit_norm)
But I get the error
> fn = function (p) ':method 'L-BFGS-B' requires finite values of fn"回答 1
Stack Overflow用户
发布于 2021-01-24 20:11:53
这里有很多问题。主要的问题是,您的可能性表达式是错误的(您不能单独记录组件,然后添加它们,您必须添加组件,然后获取日志)。你的界限也很有趣:混合概率应该是0,1,平均值应该是0,Inf。
另一个问题是,使用当前的模拟设计(n=20,prob=0.01),在第一个混合分量中获得无点的概率很高(第二个分量中一个点的概率为1-0.01=0.99,所以所有点都在第二个分量中的概率为0.99^20 = 82%)。在这种情况下,MLE将退化(也就是说,您试图将两个组分混合到一个数据集中,该数据集实际上只有一个组件);在这种情况下,这些解决方案中的任何一个都会给出等效的可能性:
mu1=anything
- prob=1,
- prob=0,mu2=mean of the data, mu1=mean of the data,prob=anything
有了所有这些解决方案,您的最终结果将非常敏感地取决于启动条件和优化算法。
对于这个问题,我鼓励您使用来自包的内置 dmixexp2函数(它正确地将日志可能性实现为log(p*Prob(X|exp1) + (1-p)*Prob(X|exp2)))和到mle2的公式接口。
fit_norm <- mle2(X ~ dmixexp2(rate1=1/mu1,rate2=1/mu2,prob1=eps),
data=list(X=X),
start = list(mu1=1, mu2 = 2, eps=0.4),
lower = c(mu1=0, mu2=0, eps=0),
upper = c(mu1=Inf, mu2=Inf, eps=1),
method = 'L-BFGS-B')这给了我mu1=1.58,mu2=2.702,eps=0的估计。在我的例子中,mean(X)等于mu2的值,所以这是上面项目符号列表中的第一个例子。你也会收到警告:
一些参数在边界上:基于Hessian的方差协方差计算可能不可靠。
还有多种更专业的混合模型拟合算法(尤其是基于期望最大化算法的算法);您可以在CRAN上查找包(flexmix就是其中之一)。
这个问题很小,你可以用蛮力来显示整个对数似然面(下面的代码):颜色表示偏离最小负对数似然度的偏差(颜色梯度是对数缩放的,所以有一个小的偏移量来避免log(0))。深蓝色代表最适合数据的参数,黄色代表最差的参数。
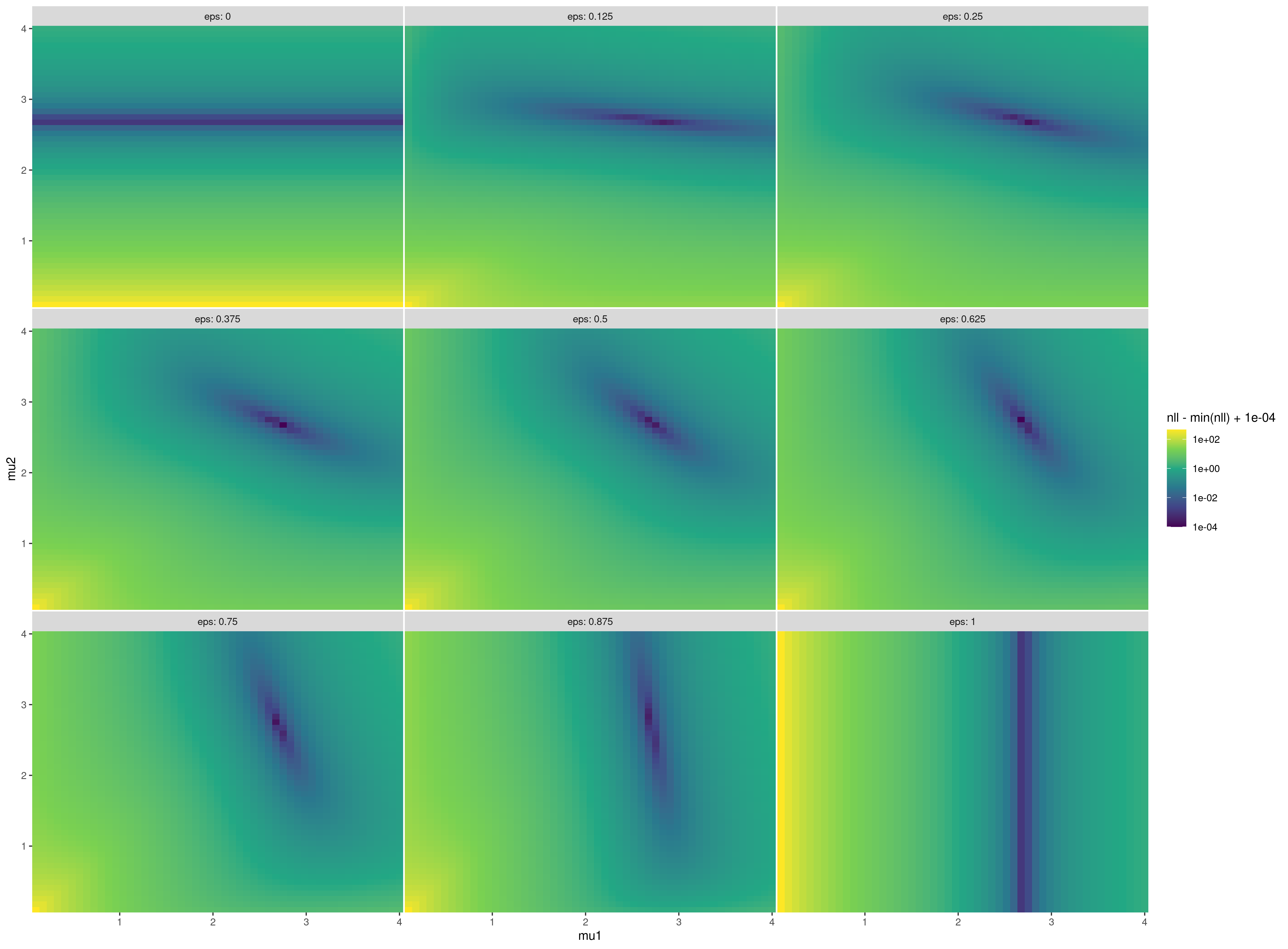
dd <- expand.grid(mu1=seq(0.1,4,length=51),
mu2=seq(0.1,4,length=51),
eps=seq(0,1,length=9),
nll=NA)
for (i in 1:nrow(dd)) {
dd$nll[i] <- with(dd[i,],
-sum(dmixexp2(X,rate1=1/mu1,
rate2=1/mu2,
prob1=eps,
log=TRUE)))
}
library(ggplot2)
ggplot(dd,aes(mu1,mu2,fill=nll-min(nll)+1e-4)) +
facet_wrap(~eps, labeller=label_both) +
geom_raster() +
scale_fill_viridis_c(trans="log10") +
scale_x_continuous(expand=c(0,0)) +
scale_y_continuous(expand=c(0,0)) +
theme(panel.spacing=grid::unit(0.1,"lines"))
ggsave("fit_norm.png", type="cairo-png")https://stackoverflow.com/questions/65874044
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号