
线性趋势上使用pykalman的卡尔曼滤波器给出了正确的答案吗?
线性趋势上使用pykalman的卡尔曼滤波器给出了正确的答案吗?
提问于 2021-01-25 13:16:57
我试图用KalmanFilter来估计一个序列的平均值,但是我找不到很多关于线性趋势的相关信息,所以我试图用它来预测当输入只是一条正斜率的直线时的值。
from pykalman import KalmanFilter as KF
y=np.arange(0,100,1)
y=pd.DataFrame(y)
x=y.shift(1)
x=pd.DataFrame(x,index=np.arange(0,100,1))
kf = KF(transition_matrices = [1],
observation_matrices = [1],
initial_state_mean = 10,
initial_state_covariance = 1,
observation_covariance=1,
transition_covariance=.01)
state_means, _ = kf.filter(x.dropna().values)
d={'a':np.asarray(x),'b':np.asarray(state_means)}
sm = pd.DataFrame(state_means,index=x.index[:-1],columns=['state'])
sma=x.rolling(window=10).mean()
x['kalman']=sm
x['rolling']=sma
x.plot(figsize=(10,8))我能够应用,但我不确定这是否正确。我看到实际值和kalman状态值之间的差距:
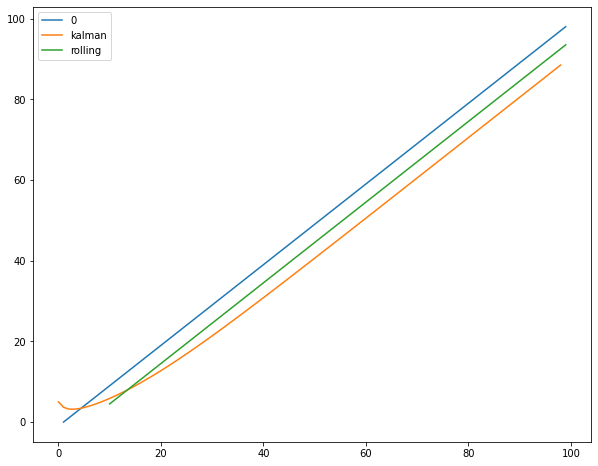
。
我原以为KalmanFilter会完成这个空白,最终与直线重合,但过了一段时间,它们似乎是平行的。
这是对的还是我做错了什么?
回答 1
Stack Overflow用户
发布于 2021-01-26 06:57:34
下面是我在评论中共享的代码。
from pykalman import KalmanFilter as KF
import numpy as np
import pandas as pd
y=np.arange(0,100,1)
y=pd.DataFrame(y)
x=y.shift(1)
x=pd.DataFrame(x,index=np.arange(0,100,1))
kf = KF(initial_state_mean=0, n_dim_obs=1)
#kf = kf.em(x.dropna().values, n_iter=5)
state_means, _ = kf.filter(x.dropna().values)
d={'a':np.asarray(x),'b':np.asarray(state_means)}
sm = pd.DataFrame(state_means,index=x.index[:-1],columns=['state'])
sma=x.rolling(window=10).mean()
x['kalman']=sm
x['rolling']=sma
x.plot(figsize=(10,8))
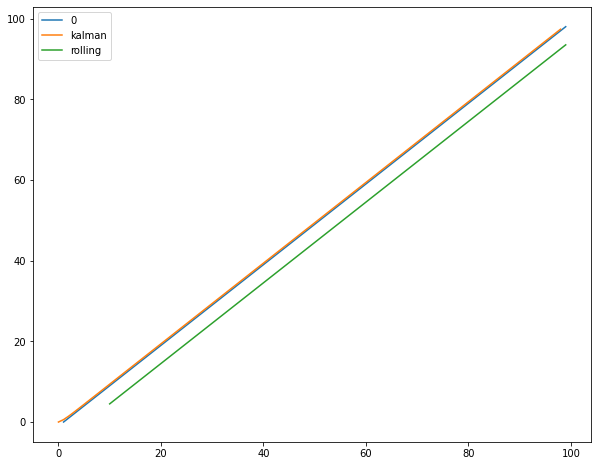
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65885522
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号