
为什么剪枝参数在tensorflow的tfmot中增加
为什么剪枝参数在tensorflow的tfmot中增加
提问于 2021-02-07 16:43:42
我修剪了一个模型,并遇到了一个库TensorFlow模型优化,因此,最初,我们有
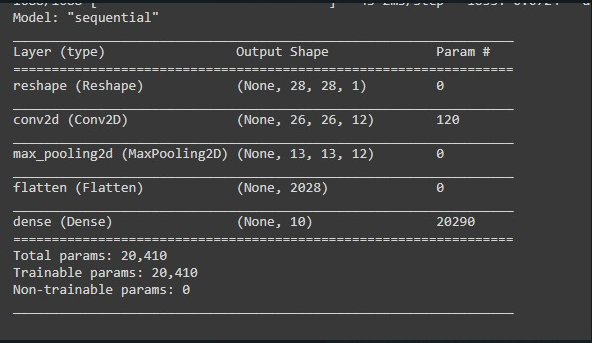
我在一个默认的数据集上训练了这个模型,它给了我96 %的准确率,这是很好的。然后,我将模型保存在JSON文件中,并将模型的权重保存在h5文件中,现在我将该模型加载到另一个脚本中,以便在应用剪枝和编译模型之后对其进行剪枝,得到了模型摘要。
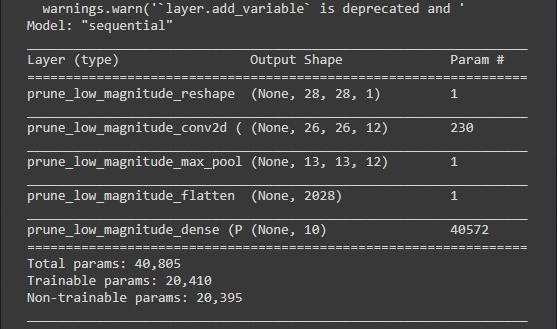
虽然模型修剪得很好,参数也有了很大的减少,但是问题是为什么参数在应用修剪后会增加,而且即使在重新移动不可训练的参数之后,修剪和简单的模型仍然有相同数量的参数,任何人都可以解释我这是正常的还是我做错了什么。另外,请解释为什么会发生这种情况。预先谢谢各位:)
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-02-07 17:35:50
这是正常的。剪枝不会改变原模型的结构。因此,这并不意味着要减少参数的数量。
剪枝是一种模型优化技术,它消除了不常用的(换句话说,可以说是不必要的)权重值。
第二个模型摘要显示了为剪枝而增加的参数。它们是不可训练的参数。不可训练参数表示掩蔽.简而言之,tensorflow为网络中的每个权重添加了不可训练的掩码,以指定哪些权重应该被剪短。面具由0和1组成。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/66090385
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号