
如何从html标记中的wikipedia术语条目中提取文本摘要?
如何从html标记中的wikipedia术语条目中提取文本摘要?
提问于 2021-02-24 00:47:35
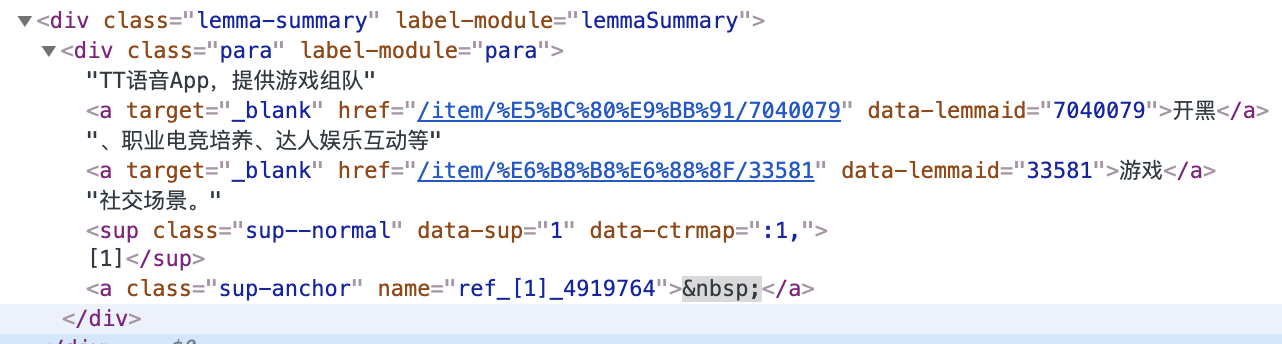
在所附的html屏幕截图中,我希望在‘引理-摘要’部分获得文本摘要。这通常是维基百科条目的第一句话。这是一个中文维基百科条目。我通过BeautifulSoup使用了这段代码
summaries = doc.getElements('div', attr='label-module', value='para').text 但这将返回html页面的所有文本部分,而不使用“引理-摘要”。如果我这么做:
summary = soup.select(".lemma-summary")这确实给出了正确的部分(只有摘要部分),但是它返回一个ResultSet对象,而且我不知道如何处理确切的文本部分。
如何从这个标签中提取文本部分?
页面的URL在这里:
https://baike.baidu.com/item/tt%E8%AF%AD%E9%9F%B3我想摘录以下摘要:
"ika是深圳缇卡基因美容生物科技有限公司的一个化妆品品牌。"回答 1
Stack Overflow用户
回答已采纳
发布于 2021-02-24 05:08:54
我不得不使用selenium来加载页面。如果您不需要selenium就可以得到正确的html,那么它也可以工作。
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome('chromedriver.exe', options=chrome_options)
url = 'https://baike.baidu.com/item/tt%E8%AF%AD%E9%9F%B3'
driver.get(url)
time.sleep(5)
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")这
soup.find('div', attrs={'class': 'para', 'label-module': 'para'}).text让你
'TT语音App,提供游戏组队开黑、职业电竞培养、达人娱乐互动等游戏社交场景。\n[1]\xa0\n'还有这个
summary = soup.select(".lemma-summary")
for s in summary:
print(s.text)让你
TT语音App,提供游戏组队开黑、职业电竞培养、达人娱乐互动等游戏社交场景。
[1] 页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/66343121
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号