
Kubernetes -强制重新启动特定的内存使用
我们的服务器使用Kubernetes进行自动缩放,我们使用newRelic实现可观察性,但我们面临一些问题。
1-当内存使用量达到1G时,我们需要重新启动pods,当内存达到1.2G时,它会自动重新启动,但一切都进展缓慢。
2-当没有对服务器的请求时终止吊舱
我的配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Release.Name }}
labels:
app: {{ .Release.Name }}
spec:
revisionHistoryLimit: 2
replicas: {{ .Values.replicas }}
selector:
matchLabels:
app: {{ .Release.Name }}
template:
metadata:
labels:
app: {{ .Release.Name }}
spec:
containers:
- name: {{ .Release.Name }}
image: "{{ .Values.imageRepository }}:{{ .Values.tag }}"
env:
{{- include "api.env" . | nindent 12 }}
resources:
limits:
memory: {{ .Values.memoryLimit }}
cpu: {{ .Values.cpuLimit }}
requests:
memory: {{ .Values.memoryRequest }}
cpu: {{ .Values.cpuRequest }}
imagePullSecrets:
- name: {{ .Values.imagePullSecret }}
{{- if .Values.tolerations }}
tolerations:
{{ toYaml .Values.tolerations | indent 8 }}
{{- end }}
{{- if .Values.nodeSelector }}
nodeSelector:
{{ toYaml .Values.nodeSelector | indent 8 }}
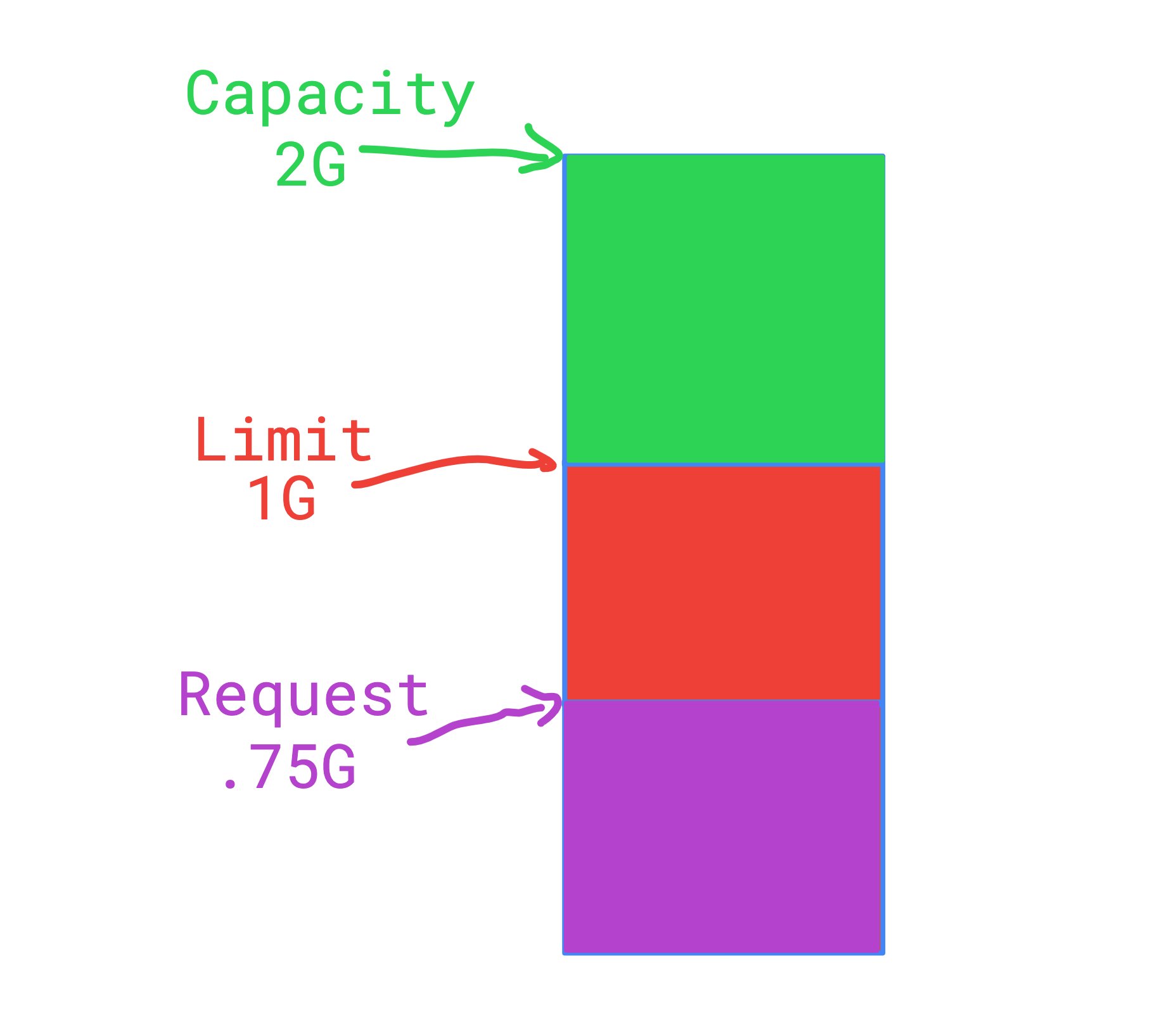
{{- end }}我的值文件
memoryLimit: "2Gi"
cpuLimit: "1.0"
memoryRequest: "1.0Gi"
cpuRequest: "0.75"这就是我想接近的
回答 1
Stack Overflow用户
发布于 2021-03-01 08:51:18
如果您想确保您的pod/部署不会消耗超过1.0Gi的内存,那么设置这个MemoryLimit就可以了。
一旦设置了这个限制,并且容器超过了限制,它就可能成为终止的候选对象。如果它继续消耗超过其限制的内存,容器将被终止。如果终止的容器可以重新启动,kubelet就会重新启动它,就像任何其他类型的运行时容器失败一样。
欲了解更多准备情况,请访问超过容器的内存限制部分
如果您希望根据请求扩展部署,则需要有外部适配器(如普罗米修斯 )提供的自定义指标。水平pod自动分频器本机只提供基于CPU和内存的扩展(基于来自度量服务器的度量标准)。
适配器文档为您提供了演练如何使用Kubernetes API和HPA配置它。其他适配器的列表可以找到这里。
然后,您可以根据http_requests度量(如这里或request-per-seconds描述的这里 )来扩展部署。
https://stackoverflow.com/questions/66404470
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号