
雪花ST_POLYGON(TO_GEOGRAPHY(…))效率低下
我有几个使用地理空间条件的查询。这些查询运行速度惊人地慢。一开始我以为是地理空间计算本身,但是把所有的东西都去掉,只剩下ST_POLYGON(TO_GEOGRAPHY(...)),它仍然很慢。如果每一行都有自己的多边形,这将是有意义的,但是条件在查询中使用静态多边形:
SELECT
ST_POLYGON(TO_GEOGRAPHY('LINESTRING(-95.75122850074004 28.793166796020444,-95.68622920563344 30.207416499279063,-94.5162418937178 32.56537633083211,-90.94128066286225 34.24734047810797,-88.17881062083825 36.812423897251634,-86.13133282498448 38.15341651409619,-85.28634198860107 38.66275098353796,-84.37635185711038 38.789523129087826,-82.84886842210855 38.4848923369382,-82.32887406125734 37.820427257446994,-82.26387476615074 36.96838022284757,-82.03637723327772 36.00158943485101,-80.99638851157454 35.34155096040939,-78.52641529752944 34.62260477275565,-77.51892622337955 34.005211031324734,-78.26641811710381 31.1020568651834,-80.24889661785029 29.926151366059756,-83.59636031583283 28.793166796020444,-95.75122850074004 28.793166796020444)'))
FROM TABLE(GENERATOR(ROWCOUNT=>1000000))雪花应该能够计算出整个查询只需要计算一次这个多边形。然而,添加的行越多,获得的速度就越慢。在x-小的情况下,这个查询需要超过一分钟。其中,此查询:
SELECT
'LINESTRING(-95.75122850074004 28.793166796020444,-95.68622920563344 30.207416499279063,-94.5162418937178 32.56537633083211,-90.94128066286225 34.24734047810797,-88.17881062083825 36.812423897251634,-86.13133282498448 38.15341651409619,-85.28634198860107 38.66275098353796,-84.37635185711038 38.789523129087826,-82.84886842210855 38.4848923369382,-82.32887406125734 37.820427257446994,-82.26387476615074 36.96838022284757,-82.03637723327772 36.00158943485101,-80.99638851157454 35.34155096040939,-78.52641529752944 34.62260477275565,-77.51892622337955 34.005211031324734,-78.26641811710381 31.1020568651834,-80.24889661785029 29.926151366059756,-83.59636031583283 28.793166796020444,-95.75122850074004 28.793166796020444)'
FROM TABLE(GENERATOR(ROWCOUNT=>3000000))(增加2mm行以匹配字节计数)
可以在2s内完成。
我自己尝试用WITH语句“预计算”多边形,但是SF发现WITH是多余的,并删除了它。我也尝试过设置一个session变量,但是不能将像这个值这样的复杂值设置为变量。
我相信这是个窃听器。
回答 1
Stack Overflow用户
发布于 2021-03-04 03:53:57
地理空间功能目前还处于预览阶段,该团队正在努力进行各种优化。
对于这种情况,我想指出的是,使多边形成为一个单行表会有帮助,但我仍然期望得到更好的性能,因为团队从beta版中获得了这个特性。
让我创建一个只有一行的表,多边形:
create or replace temp table poly1
as
select ST_POLYGON(TO_GEOGRAPHY('LINESTRING(-95.75122850074004 28.793166796020444,-95.68622920563344 30.207416499279063,-94.5162418937178 32.56537633083211,-90.94128066286225 34.24734047810797,-88.17881062083825 36.812423897251634,-86.13133282498448 38.15341651409619,-85.28634198860107 38.66275098353796,-84.37635185711038 38.789523129087826,-82.84886842210855 38.4848923369382,-82.32887406125734 37.820427257446994,-82.26387476615074 36.96838022284757,-82.03637723327772 36.00158943485101,-80.99638851157454 35.34155096040939,-78.52641529752944 34.62260477275565,-77.51892622337955 34.005211031324734,-78.26641811710381 31.1020568651834,-80.24889661785029 29.926151366059756,-83.59636031583283 28.793166796020444,-95.75122850074004 28.793166796020444)'
)) polygon
;为了看看这是否有用,我尝试了一百万行交叉连接:
select *
from poly1, TABLE(GENERATOR(ROWCOUNT=>1000000));这需要14秒,在查询分析器中,您可以看到大部分时间都花在了内部TO_OBJECT(GET_PATH(POLY1.POLYGON, '_shape')上。
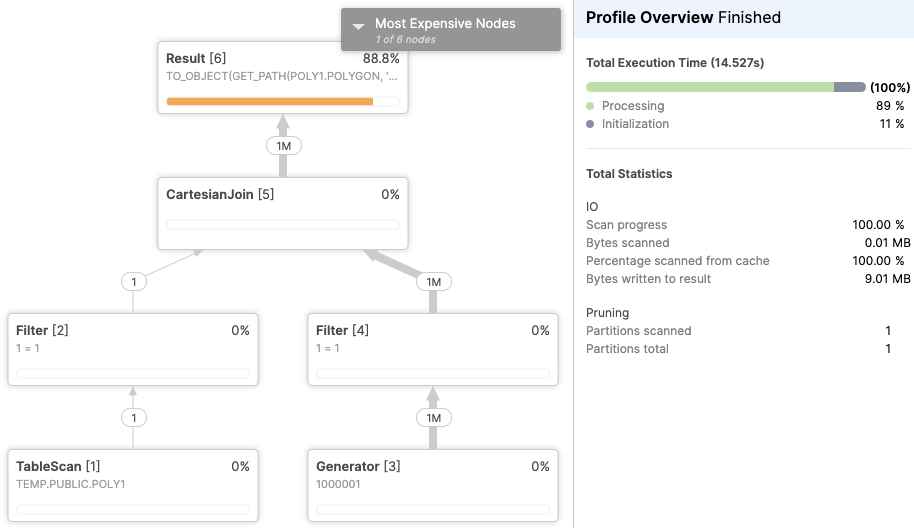
有趣的是,前面的操作主要涉及多边形的ascii表示。在这个多边形上运行操作要快得多:
select st_area(polygon)
from poly1, TABLE(GENERATOR(ROWCOUNT=>1000000));这个查询应该花更长的时间(找到多边形的区域听起来比选择它更复杂),但是结果证明它只花了7秒(~一半)。
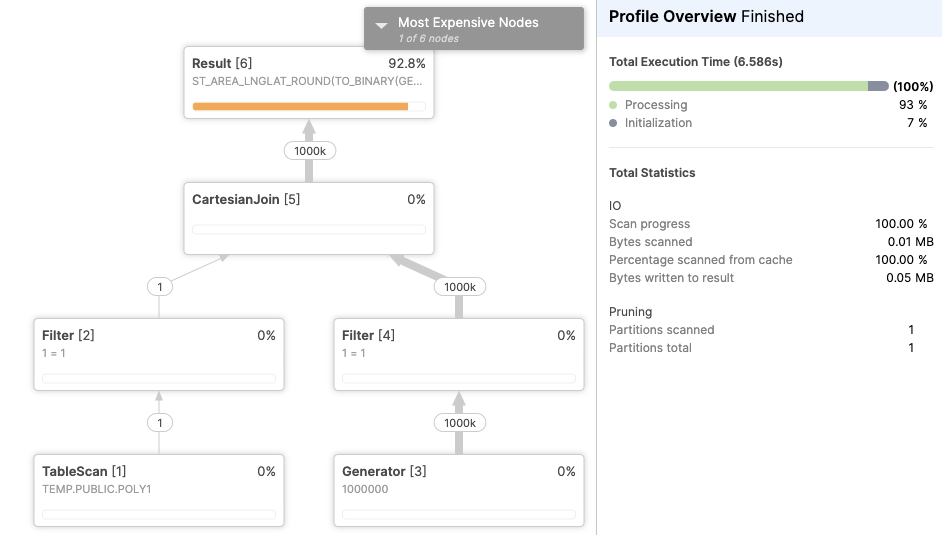
感谢您的报告,团队将继续优化这样的案例。
对于任何对问题中的特定多边形感兴趣的人来说--这是一颗善良的心:
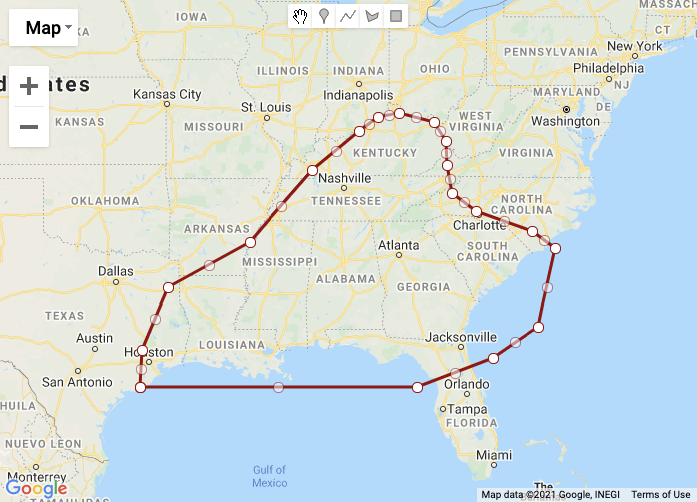
https://stackoverflow.com/questions/66465960
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号