
从网页中抓取数据属性
从网页中抓取数据属性
提问于 2021-03-10 12:14:30
你好,我是一个新的网络刮刮和我有一个问题。我想要从这个html代码中刮取数据:
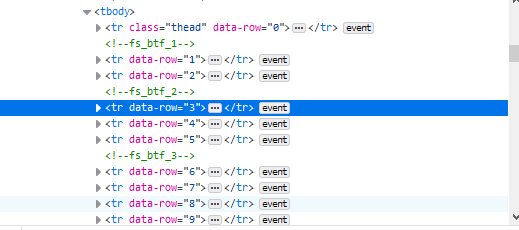
我希望拥有属于
<tr> .. </tr> 标签。
我的代码如下所示:
from bs4 import BeautifulSoup
import requests
html_text = requests.get('https://www.basketball-reference.com/leagues/').text
soup = BeautifulSoup(html_text, 'lxml')
rows = soup.select('tr[data-row]')
print(rows)我受到这个thread的启发,但它正在返回一个空数组。有人能帮我吗
回答 2
Stack Overflow用户
回答已采纳
发布于 2021-03-10 12:22:57
如何使用pandas使您的网络抓取生活(有点)更容易?
下面是操作步骤:
import pandas as pd
import requests
df = pd.read_html(requests.get('https://www.basketball-reference.com/leagues/').text, flavor="bs4")
df = pd.concat(df)
df.to_csv("basketball_table.csv", index=False)输出:

Stack Overflow用户
发布于 2021-03-10 12:37:48
正如我在评论中所说的,似乎在客户端添加了属性data-row --我在HTML中找不到它。
解决这个问题的一个简单快捷的方法是更改css选择器。我想出了这样的东西
rows = soup.select('tr')
for row in rows:
if row.th.attrs['data-stat']=='season' and 'scope' in row.th.attrs:
print(row)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/66564598
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号