
由多峰分布确定的单峰分布图
我使用GaussianMixture来分析多模式分布。从GaussianMixture类中,我可以使用属性means_和covariances_访问均值和协方差。现在如何使用它们来绘制两个基本的单峰分布呢?
我考虑使用scipy.stats.norm,但不知道如何为loc和scale选择参数。所需的输出将类似于所附图所示。
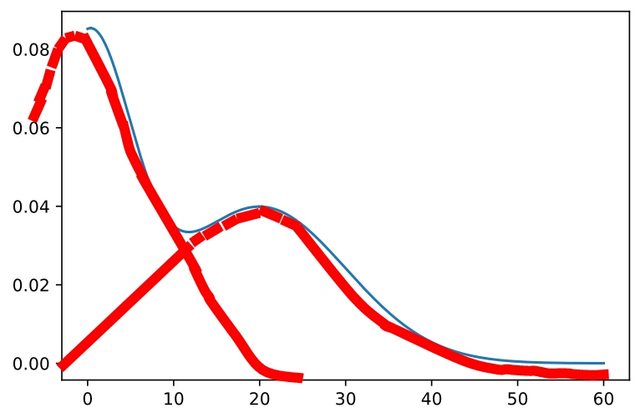
这个问题的示例代码是从答案这里中修改的。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import mixture
from scipy.stats import norm
ls = np.linspace(0, 60, 1000)
multimodal_norm = norm.pdf(ls, 0, 5) + norm.pdf(ls, 20, 10)
plt.plot(ls, multimodal_norm)
# concatenate ls and multimodal to form an array of samples
# the shape is [n_samples, n_features]
# we reshape them to create an additional axis and concatenate along it
samples = np.concatenate([ls.reshape((-1, 1)), multimodal_norm.reshape((-1,1))], axis=-1)
print(samples.shape)
gmix = mixture.GaussianMixture(n_components = 2, covariance_type = "full")
fitted = gmix.fit(samples)
print(fitted.means_)
print(fitted.covariances_)
# The idea is something like the following (not working):
new_norm1 = norm.pdf(ls, fitted.means_, fitted.covariances_)
new_norm2 = norm.pdf(ls, fitted.means_, fitted.covariances_)
plt.plot(ls, new_norm1, label='Norm 1')
plt.plot(ls, new_norm2, label='Norm 2')回答 1
Stack Overflow用户
发布于 2021-03-14 16:19:08
还不完全清楚你想要完成什么。您正在将一个GaussianMixture模型拟合到一个均匀网格上采样的两个高斯人的pdfs值的和和,以及来自网格本身的值之和。这不是用来拟合高斯混合模型的方法。通常,一个模型适合于从某种分布中提取的随机观测(通常未知,但可以是模拟的)。
让我假设您想要将GaussianMixture模型与从高斯混合分布中提取的样本进行拟合。假设您知道预期结果是什么,那么大概是为了测试fit的工作效果。下面是这样做的代码,既可以模拟正确的分布,也可以适应模型。它打印从样本中恢复的拟合参数--我们观察到它们确实接近我们用来模拟样本的参数。最后生成适合于数据的GaussianMixture分布的密度图。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import mixture
from scipy.stats import norm
# set simulation parameters
mean1, std1, w1 = 0,5,0.5
mean2, std2, w2 = 20,10,1-w1
# simulate constituents
n_samples = 100000
np.random.seed(2021)
gauss_sample_1 = np.random.normal(loc = mean1,scale = std1,size = n_samples)
gauss_sample_2 = np.random.normal(loc = mean2,scale = std2,size = n_samples)
binomial = np.random.binomial(n=1, p=w1, size = n_samples)
# simulate gaussian mixture
mutlimodal_samples = (gauss_sample_1 * binomial + gauss_sample_2 * (1-binomial)).reshape(-1,1)
# define and fit the mixture model
gmix = mixture.GaussianMixture(n_components = 2, covariance_type = "full")
fitted = gmix.fit(mutlimodal_samples)
print('fitted means:',fitted.means_[0][0],fitted.means_[1][0])
print('fitted stdevs:',np.sqrt(fitted.covariances_[0][0][0]),np.sqrt(fitted.covariances_[1][0][0]))
print('fitted weights:',fitted.weights_)
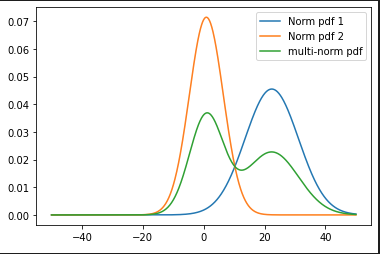
# Plot component pdfs and a joint pdf
ls = np.linspace(-50, 50, 1000)
new_norm1 = norm.pdf(ls, fitted.means_[0][0], np.sqrt(fitted.covariances_[0][0][0]))
new_norm2 = norm.pdf(ls, fitted.means_[1][0], np.sqrt(fitted.covariances_[1][0][0]))
multi_pdf = w1*new_norm1 + (1-w1)*new_norm2
plt.plot(ls, new_norm1, label='Norm pdf 1')
plt.plot(ls, new_norm2, label='Norm pdf 2')
plt.plot(ls, multi_pdf, label='multi-norm pdf')
plt.legend(loc = 'best')
plt.show()结果是
fitted means: 22.358448018824642 0.8607494960575028
fitted stdevs: 8.770962351118127 5.58538485134623
fitted weights: [0.42517515 0.57482485]正如我们所看到的,它们与模拟中的内容非常接近(按照它们的顺序,当然模型无法恢复,但无论如何都是无关紧要的):
mean1, std1, w1 = 0,5,0.5
mean2, std2, w2 = 20,10,1-w1以及密度及其各部分的图。回想一下,GaussianMixture的pdf是,而不是,它是pdfs的和,而是加权平均值w1,1-w1。
https://stackoverflow.com/questions/66626226
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号