
获得一个包含名称的句子的Regex
我正在创建一个正则表达式,如果一个特定的信息存在的话,它可以得到整个句子。现在我正在研究我的名字regex,所以如果有任何组合名称(例如:"Jorge Martel","Jorge Martel del Arnold Albuquerque"),regex应该得到有名称的整个句子。
如果我有以下两句话:
(1) --“一个勤劳的人在超市工作,他们叫他豪尔赫·霍瑞森,但那不是他的真名。”
(2) --“他有一份载有豪尔赫·马特尔·阿诺德姓名的身份证件。”
regex应该从上面的句子中返回以下两个结果:
(1)“他们叫他豪尔赫·奥里森,但那不是他的真名。”
(2) --“他有一份载有豪尔赫·马特尔·阿诺德姓名的身份证件。”
这是我的准则:
(?:(?(?<=[\.!?]\s([A-Z]))(.+?[^.])|))?((?:(?:[A-Z][A-zÀ-ÿ']+\s(?:(?:(?:[A-zÀ-ÿ']{1,3}\s)?(?:[A-ZÀ-Ÿ][A-zÀ-ÿ']*\s?))+))\b)(.+?[\.!?](?:\s|\n|\Z)))基本上,它会验证是否有一个带空格和大写字符的点、感叹号或询问符号,并告诉正则表达式一切都必须选择,否则它就会得到所有的句子。
现在我的其他情况是空的,因为使用(.+?)避开我的第一个条件..。
没有其他情况的Regex:
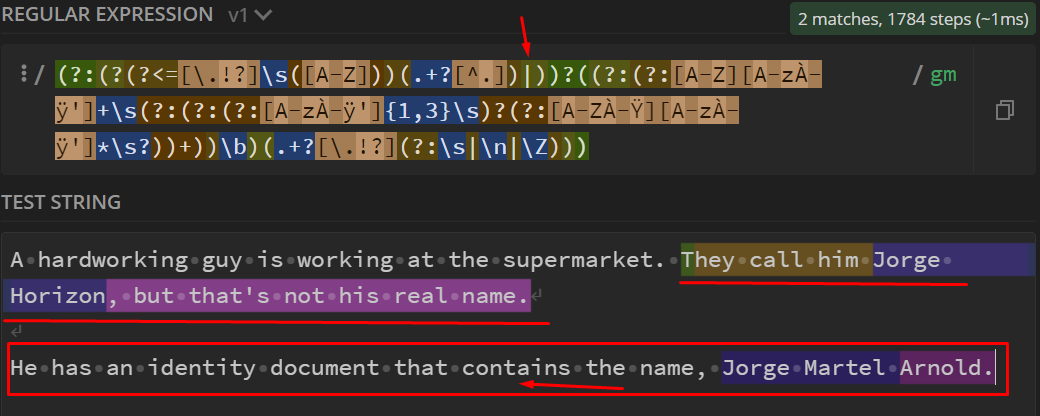
验证直到点,但没有得到第二句。
其他情况下的Regex:
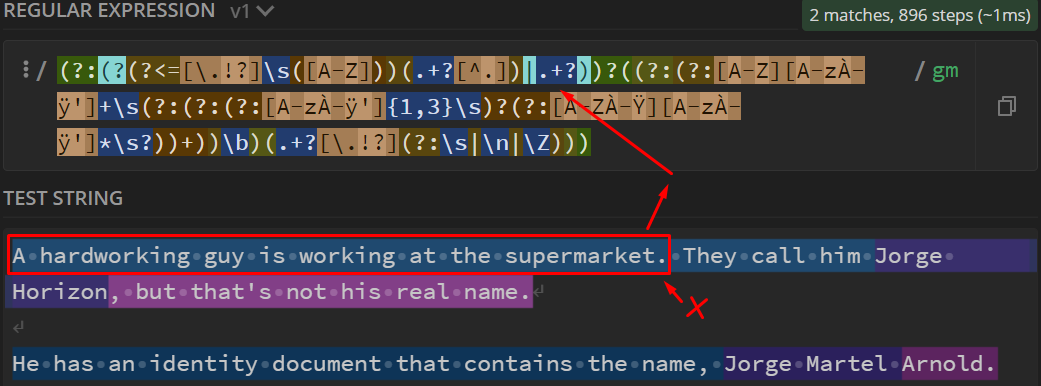
验证第二句,但重写第一句中出现的第一个条件。
我希望我的准则能正确地返回以下句子:
- “他们叫他豪尔赫·奥里森,但那不是他的真名。”
- “他有一份身份证件,上面有豪尔赫·马特尔·阿诺德( Jorge Martel Arnold)。”
我还创建了一个文本来验证regex操作,因为我将在文本中大量使用它。我在这篇文章中添加了很多条件,这可能会出现在我的日常工作中。
检查我的正则表达式、句子和文本这里
有人知道我该改变什么吗?我尝试了许多不同的方法,但仍然找不到解决办法。
P.S.:我打算在我的python代码中使用它,但是我需要用regex而不是python代码来修复它。
回答 3
Stack Overflow用户
发布于 2021-03-16 14:40:51
试试这个:
((?:^|(?:[^\.!?]*))[^\.!?\n]*(?:(?:[A-ZÀ-Ÿ][A-zÀ-ÿ']+\s?){2,}[^\.!?]*[\.!?]))它将捕获名称至少有两个单词的句子,例如His name is John Smith.
它不会捕获像:John went to a concert.这样的句子
Stack Overflow用户
发布于 2021-03-16 15:10:12
你可以试试这个。
[\w\ \,\']+\.\ ?([\w\ \,\']+\.)|^([\w\ \,\']+\.)$打印$1$2。也就是说,如果第一组为空,则打印空白,因为没有匹配,那么将打印组2。相反,当第2组不存在时,打印组1。
\W,'+.\?(\W,'+.) -作为与XXX匹配的任何东西。某某。
然后
^(\w\,'+.)$ -必须以一个句子开头。
尽管诚实地说,这可以很容易地用Tokenizer of (.)来完成。它的长度是1或2,就像用大锤敲钉子一样。
Stack Overflow用户
发布于 2021-03-16 15:22:50
使用正则表达式匹配名称可能是一项非常困难的工作,但是如果要使用指定的范围匹配至少两个连续的大写单词。
假设名称以大写字符a开头(否则您也可以用允许的字符扩展该字符类,或者如果支持的话,可以使用\p{Lu}来匹配大写字符,该字符具有小写变体):
(?<!\S)[A-Z][A-Za-zÀ-ÿ]*(?:\s+[a-zÀ-ÿ,]+)*\s+[A-Z][a-zÀ-ÿ]*\s+[A-Z][a-zÀ-ÿ,]*.*?[.!?](?!\S)(?<!\S)断言左边的空白边界[A-Z][A-Za-zÀ-ÿ]*可选地匹配大写字符A-Z,然后匹配定义的范围(?:\s+[a-zÀ-ÿ,]*)*可选择性地重复匹配1+空白字符和一个或多个范围\s+[A-Z][a-zÀ-ÿ]*\s+[A-Z][a-zÀ-ÿ,]*匹配2次空格字符,后面跟着字符类中定义的大写字母A和可选字符.*?[.!?]匹配尽可能少的字符,后面跟着.、!或?中的一个(?!\S)断言右边的空白边界
https://stackoverflow.com/questions/66657085
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号