
使用python格式化excel并在excel中写入
使用python格式化excel并在excel中写入
提问于 2021-03-19 07:11:36
我有一个未格式化的excel表作为输入文件.我需要重新安排和写入另一个excel文件。我需要计算在不同项目和不同客户中工作的电磁脉冲工作小时数。
这里RAM仅在第一个项目中工作,但mohan在第一个和第二个项目中工作,我们必须计算他的第一和第二工作人力资源。
输入
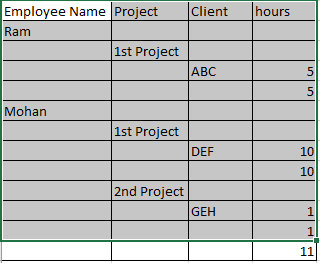
输出
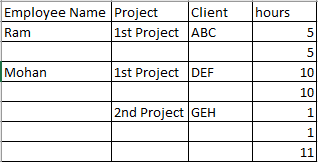
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-03-19 08:20:57
>>> df # input dataframe
Employee Name Project Client hours
0 Ram NaN NaN NaN
1 NaN 1st Project NaN NaN
2 NaN NaN ABC 5.0
3 NaN NaN NaN 5.0
4 Mohan NaN NaN NaN
5 NaN 1st Project NaN NaN
6 NaN NaN DEF 10.0
7 NaN NaN DEF 10.0
8 NaN 2nd Project NaN NaN
9 NaN NaN GEH 1.0
10 NaN NaN NaN 1.0
11 NaN NaN NaN 11.0对于除最后一列之外的每一列,将NaN替换为以前的值,并将该列移至索引,然后删除所有为空的行。最后,删除初始RangeIndex。
for col in df.columns[:-1]:
df[col] = df[col].ffill()
df = df.set_index(col, append=True)
df = df.dropna(how="all")
df = df.droplevel(0)>>> df # output dataframe
hours
Employee Name Project Client
Ram 1st Project ABC 5.0
ABC 5.0
Mohan 1st Project DEF 10.0
DEF 10.0
2nd Project GEH 1.0
GEH 1.0
GEH 11.0编辑:输出正确的excel文件
df.set_index("hours", append=True).to_excel("output.xlsx")页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/66703907
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号