
tf.data.Dataset.interleave()与map()和flat_map()究竟有什么不同?
我目前的理解是:
Different map_func:interleave和flat_map都期望“将dataset元素映射到dataset的函数”。相反,map期望“将dataset元素映射到另一个dataset元素的函数”。
参数:interleave和map都提供参数num_parallel_calls,而flat_map没有。此外,交织提供了这些神奇的论点block_length和cycle_length。对于cycle_length=1,文档声明交织和flat_map的输出是相等的。
最后,我看到了无交织的数据加载管道和带交错的。任何关于何时使用interleave与map或flat_map的建议将不胜感激。
//编辑:如果我们从不同的数据集开始,比如在下面的代码中,我确实看到了交织的值
files = tf.data.Dataset.list_files("/path/to/dataset/train-*.tfrecord")
dataset = files.interleave(tf.data.TFRecordDataset)但是,在下面这样的场景中使用interleave而不是map是否有什么好处呢?
files = tf.data.Dataset.list_files("/path/to/dataset/train-*.png")
dataset = files.map(load_img, num_parallel_calls=tf.data.AUTOTUNE)回答 1
Stack Overflow用户
发布于 2021-03-24 11:14:16
编辑:
映射也可以用于并行I/O吗?
实际上,您可以使用map函数从目录中读取图像和标签。假设这个案例:
list_ds = tf.data.Dataset.list_files(my_path)
def process_path(path):
### get label here etc. Images need to be decoded
return tf.io.read_file(path), label
new_ds = list_ds.map(process_path,num_parallel_calls=tf.data.experimental.AUTOTUNE)注意,现在它是多线程的,因为已经设置了num_parallel_calls。
interlave()函数的优点是:
- 假设您有一个数据集
- 使用
cycle_length,您可以从dataset中取出许多元素,即5,然后从dataset中取出5个元素,并且可以应用map_func。 - 然后,从新生成的对象中获取dataset对象,每次都提取
block_length数据段。
换句话说,interleave()函数c在应用a map_func()时迭代数据集。此外,它还可以同时处理许多数据集或数据文件。例如,从医生那里
dataset = dataset.interleave(lambda x:
tf.data.TextLineDataset(x).map(parse_fn, num_parallel_calls=1),
cycle_length=4, block_length=16)但是,在像下面这样的场景中使用交错映射有什么好处吗?
interleave()和map()看起来有点相似,但它们的用例并不相同。如果您想在应用某些映射时读取dataset,interleave()是您的超级英雄。您的图像可能需要解码时,被阅读。首先读取所有数据,在处理大型数据集时,解码可能效率低下。在您给出的代码片段AFAIK中,带有tf.data.TFRecordDataset的代码段应该更快。
TL;DR interleave()通过交错I/O操作来读取文件来并行数据加载步骤。
map()将将数据预处理应用于数据集的内容。
所以你可以做这样的事情:
ds = train_file.interleave(lambda x: tf.data.Dataset.list_files(directory_here).map(func,
num_parallel_calls=tf.data.experimental.AUTOTUNE)tf.data.experimental.AUTOTUNE将决定缓冲区大小、CPU功率以及I/O操作的并行度。换句话说,AUTOTUNE将在运行时动态地处理该级别。
num_parallel_calls参数生成多线程,以利用多核并行任务。这样,您可以并行加载多个数据集,从而减少等待文件打开的时间;因为interleave也可以使用参数num_parallel_calls。图像采用从医生那里。
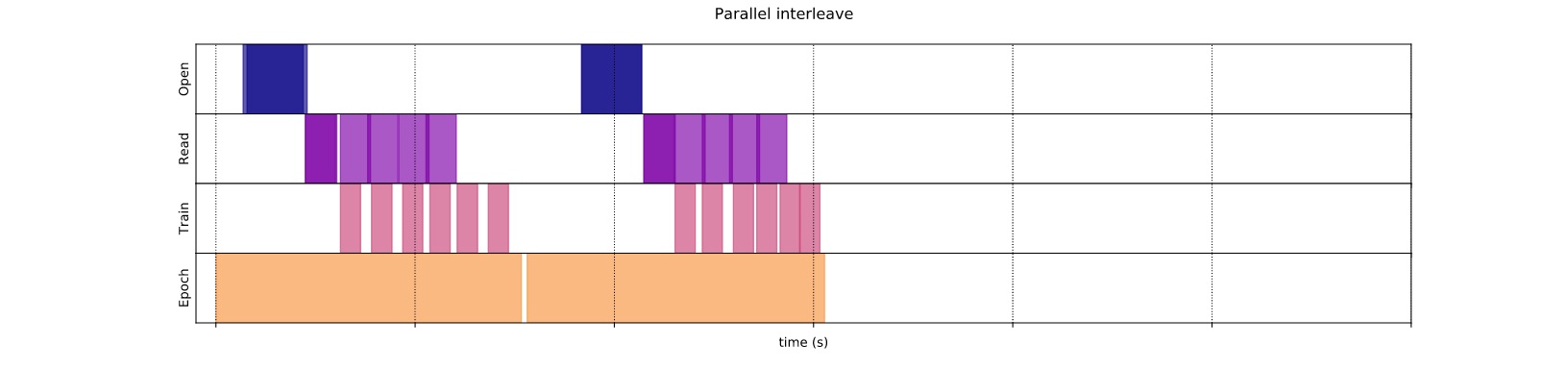
在图像中,有4个重叠的数据集,由参数cycle_length决定,因此在本例中是cycle_length = 4。
FLAT_MAP:映射跨数据集的函数,并将结果扁平化。如果您想确保订单保持不变,您可以使用这个。而且它也不以num_parallel_calls为论据。请参考文档了解更多信息。
映射: map函数将在数据集的每个元素上分别执行选定的函数。显然,随着您应用越来越多的操作,大型数据集上的数据转换可能会非常昂贵。关键是,如果CPU没有得到充分利用,它可能会更耗时。但是我们可以使用parallelism APIs
num_of_cores = multiprocessing.cpu_count() # num of available cpu cores
mapped_data = data.map(function, num_parallel_calls = num_of_cores)对于cycle_length=1,文档声明交织和flat_map的输出相等。
cycle_length ->将并发处理的输入元素的数量。当将其设置为1时,将逐个处理.
交织:转换操作(如map )可以并行化。
由于映射的并行性,CPU在转换过程中试图实现并行化,但是从磁盘中提取数据可能会造成开销。
此外,一旦将原始字节读入内存,也可能需要将函数映射到数据,这当然需要额外的计算。与解密数据等类似,需要并行处理各种数据提取开销的影响,以便通过interleaving、每个数据集的内容来减轻这种影响。
因此,在读取数据集时,您希望最大限度地:
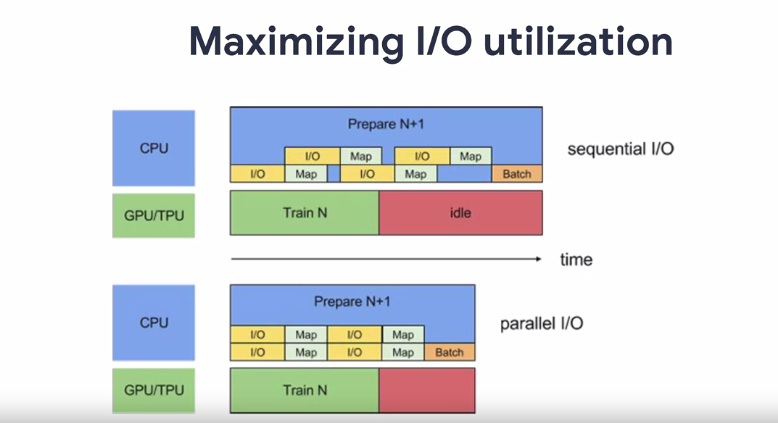
图片来源: deeplearning.ai
https://stackoverflow.com/questions/66778153
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号