
PCA中特征重要性的度量
我正在做主成分分析(PCA),我想找出哪些特性对结果的贡献最大。
我的直觉是总结所有的绝对值的个人贡献的特点,对个别的组成部分。
import numpy as np
from sklearn.decomposition import PCA
X = np.array([[-1, -1, 4, 1], [-2, -1, 4, 2], [-3, -2, 4, 3], [1, 1, 4, 4], [2, 1, 4, 5], [3, 2, 4, 6]])
pca = PCA(n_components=0.95, whiten=True, svd_solver='full').fit(X)
pca.components_array([[ 0.71417303, 0.46711713, 0. , 0.52130459],
[-0.46602418, -0.23839061, -0. , 0.85205128]])np.sum(np.abs(pca.components_), axis=0)array([1.18019721, 0.70550774, 0. , 1.37335586])在我看来,这是衡量每一个原始特性的重要性的标准。请注意,第三个特性的重要性为零,因为我有意创建了一个列,它只是一个常量值。
对常设仲裁院是否有更好的“重要性衡量”?
回答 1
Stack Overflow用户
发布于 2021-05-04 10:13:05
如果您只是单纯地将PC与np.sum(np.abs(pca.components_), axis=0)相加,那么假设所有PC都是同等重要的,这很少是正确的。将PCA应用于粗糙特征选择,剔除低贡献PC后和(或)按其相对贡献对PC进行缩放后的和。
下面是一个直观的例子,它突出了普通和不能按预期工作的原因。
给出了20个特征的3个观察结果(可视化为3个5x4热图):
>>> print(X.T)
[[2 1 1 1 1 1 1 1 1 4 1 1 1 4 1 1 1 1 1 2]
[1 1 1 1 1 1 1 1 1 4 1 1 1 6 3 1 1 1 1 2]
[1 1 1 2 1 1 1 1 1 5 2 1 1 5 1 1 1 1 1 2]]
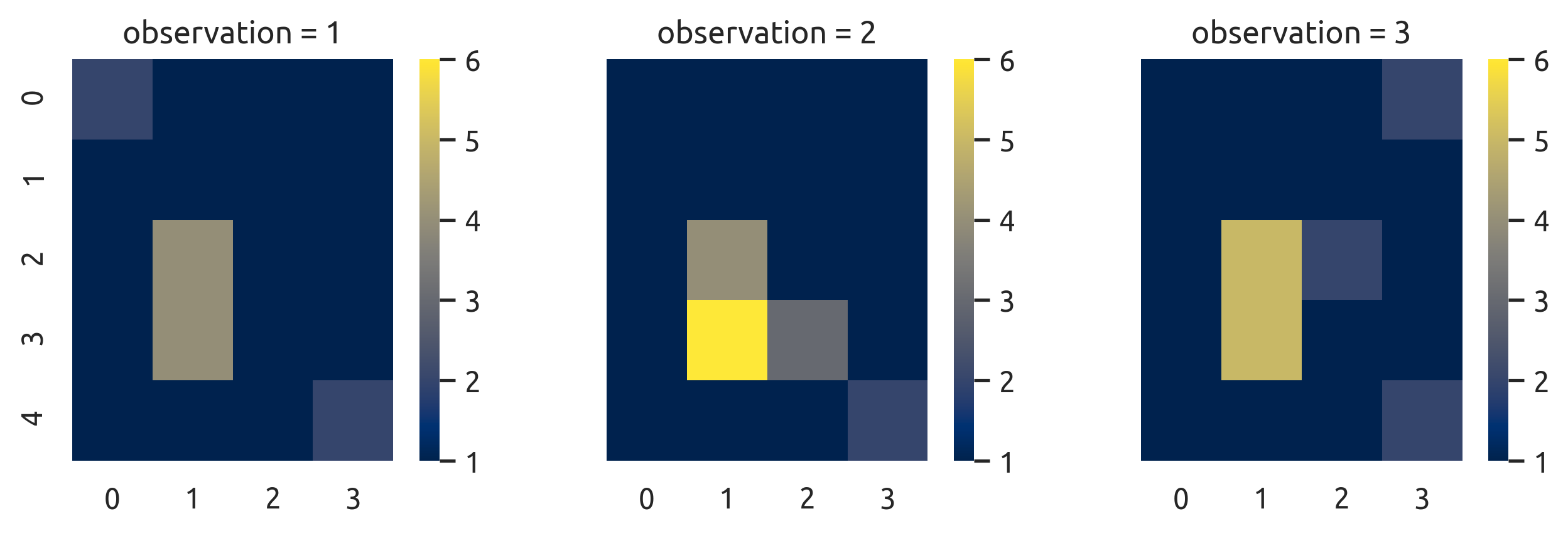
这些是由此产生的个人电脑:
>>> pca = PCA(n_components=None, whiten=True, svd_solver='full').fit(X.T)
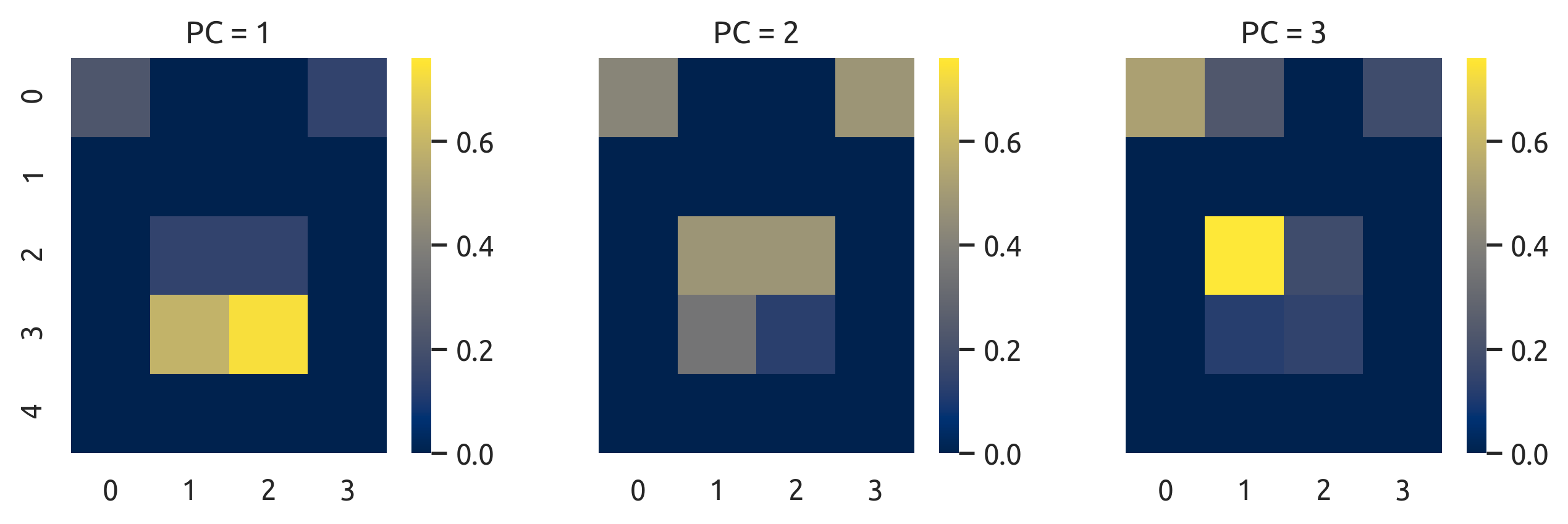
请注意,PC3在(2,1)有很高的震级,但是如果我们检查它的解释方差,它提供了~0的贡献:
>>> print(pca.explained_variance_ratio_)
array([0.6638886943392722, 0.3361113056607279, 2.2971091700327738e-32])这在将未缩放的PC(左)和按其解释的方差比(右)进行缩放的PC相加时,会导致特征选择的差异:
>>> unscaled = np.sum(np.abs(pca.components_), axis=0)
>>> scaled = np.sum(pca.explained_variance_ratio_[:, None] * np.abs(pca.components_), axis=0)
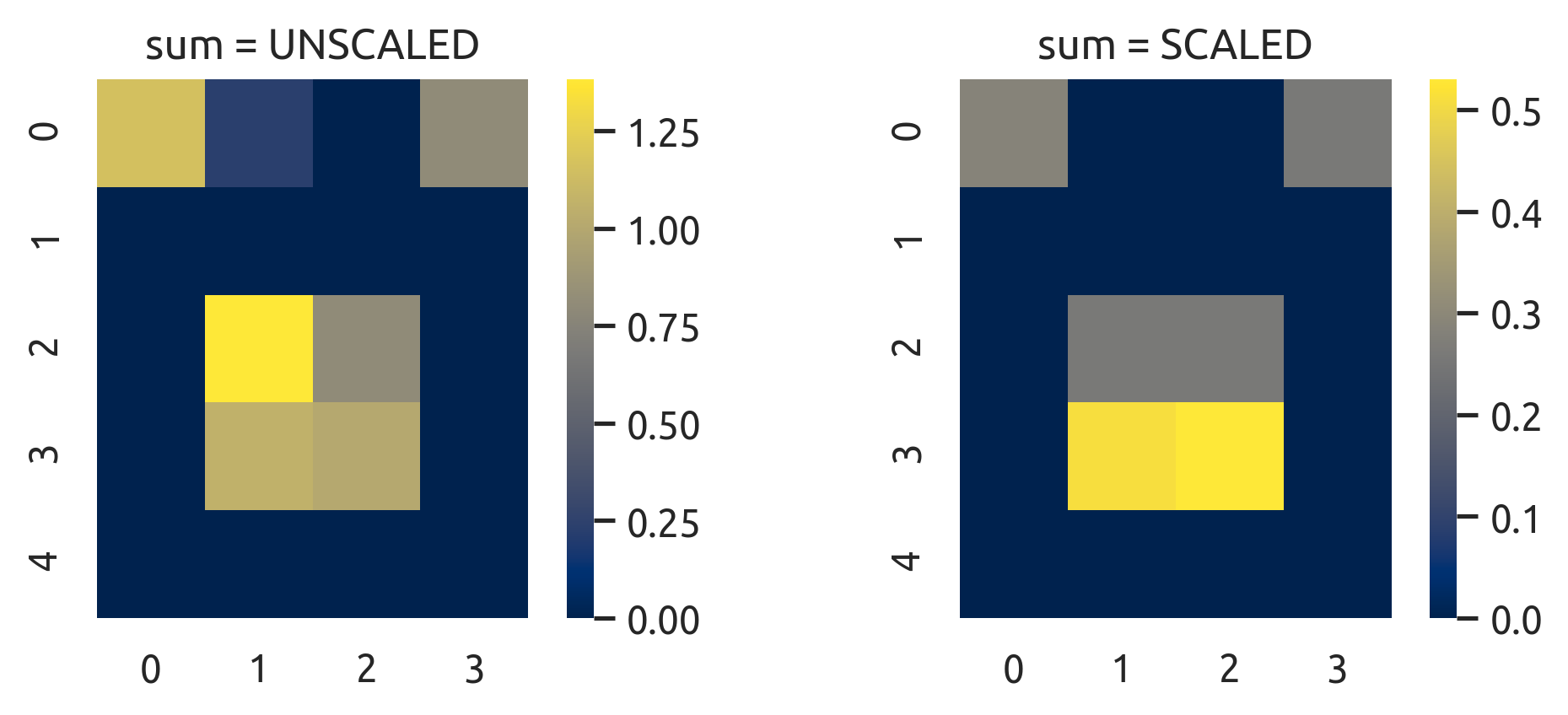
对于未缩放的和(左),无意义的PC3仍然被赋予33%的权重。这使得(2,1)被认为是最重要的特性,但是如果我们回顾一下原始数据,(2,1)提供了对观测结果的低分辨。
与比例和(右),PC1和PC2分别有66%和33%的重量。现在,(3,1)和(3,2)是真正跟踪原始数据的最重要的特性。
https://stackoverflow.com/questions/67199869
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号