
分层cox模型的拟合
分层cox模型的拟合
提问于 2021-04-23 14:27:39
我有一个分层的考克斯模型,并希望预测的生存曲线,为特定的轮廓,基于该模型。
现在,因为我使用的是一个包含很多层的大型数据集,所以我只想对非常具体的阶层进行预测,以节省时间和内存。
survfit.coxph的帮助页声明:.如果新数据包含地层变量,则根据原始模型的指示层,每一行新数据将包含一条曲线。
当我运行下面的代码(其中的newdata确实包含层变量)时,我仍然可以得到对这两个层的预测,这与帮助页相矛盾。
df <- data.frame(X1 = runif(200),
X2 = sample(c("A", "B"), 200, replace = TRUE),
Ev = sample(c(0,1), 200, replace = TRUE),
Time = rexp(200))
testfit <- coxph( Surv(Time, Ev) ~ X1 + strata(X2), df)
out <- survfit(testfit, newdata = data.frame(X1 = 0.6, X2 = "A"))这里有什么我看不懂的东西吗?
回答 2
Stack Overflow用户
发布于 2021-04-29 10:11:53
我不确定这是一个bug还是survival:::survfit.coxph中的一个特性。看起来,代码中的预期行为是只返回被请求的地层。在职能方面:
strata(X2)在包含newdata的环境中进行计算,结果将返回A。- 然后创建完整的曲线。
- 然后,有一些逻辑
split曲线进入地层,但只有当result$surv是一个矩阵。
在您的示例中,它不是矩阵。如果它不是一个bug,我就找不到任何关于它的预期使用的文档。也许值得给作者/维护人员写个便条。
maintainer("survival")
# [1] "Terry M Therneau <xxxxxxxx.xxxxx@xxxx.xxx>"Stack Overflow用户
发布于 2021-05-05 22:19:43
一些可能有帮助的评论:
- 我的例子不够大(我似乎读得不太好,但那是在我在这里提出问题之后):如果相关github员额至少有两行(当然还有分层变量),则只返回对所请求的地层的预测。
- 在
survfit.coxph内部存在效率低下的问题,其中对原始数据集中的每个层计算基线危害,而不仅仅是针对请求的层(参见我对同一个github职位的贡献)。然而,这似乎并不是什么大问题(在拥有大约50万次观测、50%事件和1000个地层的数据集上进行测试),所需时间不到一分钟。 - 问题是在计算过程中某个地方的内存分配(在上面的例子中,一旦我希望对100个观测结果进行预测--每个层有一个层),事情就会崩溃,而对80的预测的最终输出只有几MB)。
- 我的工作-周旋:
- Select all observations you want predictions for
- use `lp <- predict(..., type='lp')` to get the linear predictor for all these observations
- use survfit only on the first observation: `survfit(fit, newdata = expand_grid(newdf, strat = strata_list))`
- Store the resulting survival estimates in a data.frame (or not, that's up to you)
- To calculate predicted survival for other observations, use the PH-assumption (see formula below). This invokes the overhead of `survfit.coxph` only once and if you focus on survival on only a few times (e.g. 5- and 10-year survival), you can reduce the computer time even more
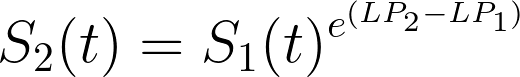
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67231786
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号