
对Python数据字典进行对比
对Python数据字典进行对比
提问于 2021-04-26 18:13:03
我遍历了一个excel文件文件夹,将它们转换为dataframes,并将这些数据文件放入字典中,其中键是文件名。我想要做的是在文件名不重要的地方制作这个大数据,因为我需要的数据的列名是唯一的。我想合并‘基因’列,因为他们重复,填充NaN分数w/零,并删除‘比率’栏。
import numpy as np
import pandas as pd
import math
import os
folder = r'C:\Users\camer\Desktop\Stack Overflow' # Folder path
files = os.listdir(folder)
dict1 = {}
for file in files:
if file.endswith('.xlsx'):
df1 = pd.read_excel(os.path.join(folder,file))
dict1[file] = df1
# Putting all excel files from file into dataframes, then setting those dataframes as the values in the preallocated dict,
# where the keys are the file names
df1 = pd.concat(dict1, axis=1)
df1
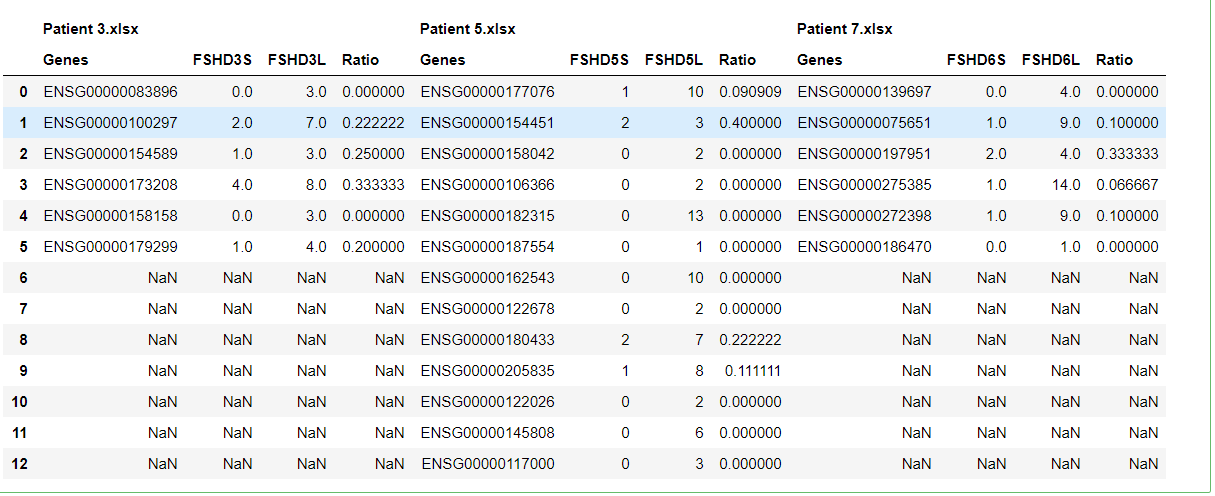
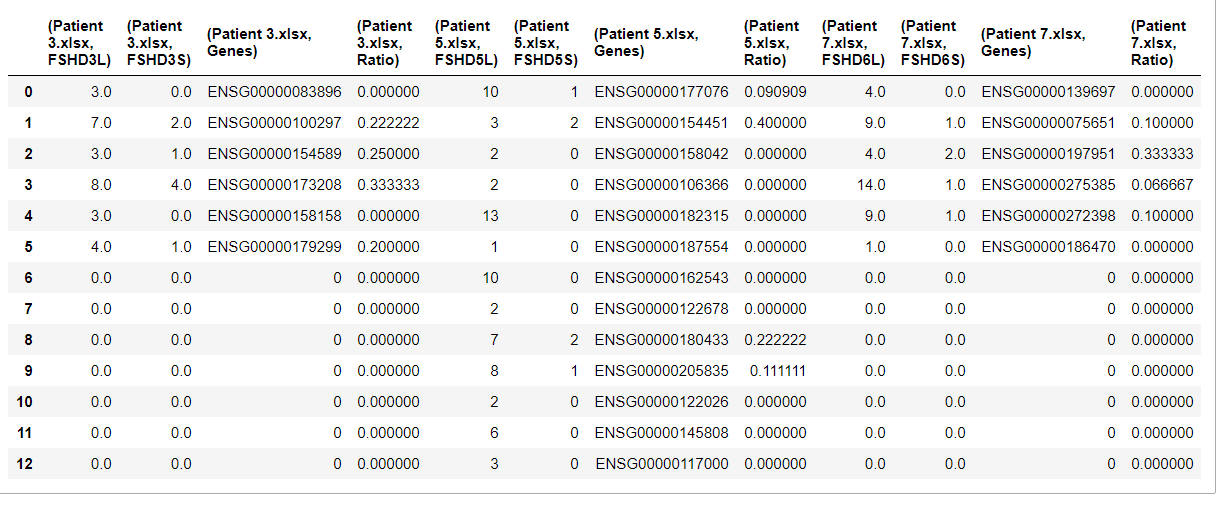
如果我试图在dataframe仍然用文件名分隔时对基因列进行分组,我会得到以下结果:
df1 = pd.concat(dict1, axis=1)
df1 = df1.groupby(df1.columns, axis=1).sum()
df1
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-04-26 18:18:44
我认为这应该适用于你:
pd.concat(dict1.values())页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67271760
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号