
如何正确检测LetsGoDigital字体文本?
如何正确检测LetsGoDigital字体文本?
提问于 2021-04-27 12:51:20
我在Windows 10上,我试图从这张图像中提取数字
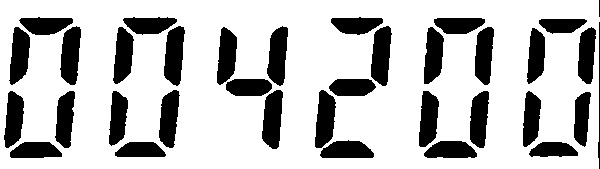
使用带有语言的pytesseract库lets (cf )。sevenSegmentsLetsGoDigital或LetsGoDigital,参比ocr)。
我预处理我的图像(灰色,阈值和侵蚀),以获得:

但是…的产出
pytesseract.image_to_string(img, lang='lets')是空的。
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-06-02 11:40:33
您没有设置任何特定的页面分割法。我会在这里选择--psm 6:
假设一个统一的文本块。
所以,即使没有进一步的预处理,我也得到了正确的结果:
import cv2
import pytesseract
img = cv2.imread('RcVbM.jpg')
text = pytesseract.image_to_string(img, lang='lets', config='--psm 6')
print(text.replace('\n', '').replace('\f', ''))
# 004200----------------------------------------
System information
----------------------------------------
Platform: Windows-10-10.0.19041-SP0
Python: 3.9.1
PyCharm: 2021.1.1
OpenCV: 4.5.2
pytesseract: 5.0.0-alpha.20201127
----------------------------------------页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67283423
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号