
如何在matplotlib中生成不同y轴的叠加线图?
我想知道我应该如何在matplotlib中使用不同的列来制作堆叠的线条图。关键是,当我们进行聚合时,我需要在两个不同的列上进行数据聚合,我想我需要制作一个大的数据,用于绘图。我在熊猫身上找不到更漂亮更方便的方法。有人能建议可能的调整来做到这一点吗?有什么想法吗?
我的尝试
这是我需要做的第一个聚合:
import pandas as pd
import matplotlib.pyplot as plt
url = "https://gist.githubusercontent.com/adamFlyn/4657714653398e9269263a7c8ad4bb8a/raw/fa6709a0c41888503509e569ace63606d2e5c2ff/mydf.csv"
df = pd.read_csv(url, parse_dates=['date'])
df_re = df[df['retail_item'].str.contains("GROUND BEEF")]
df_rei = df_re.groupby(['date', 'retail_item']).agg({'number_of_ads': 'sum'})
df_rei = df_rei.reset_index(level=[0,1])
df_rei['week'] = pd.DatetimeIndex(df_rei['date']).week
df_rei['year'] = pd.DatetimeIndex(df_rei['date']).year
df_rei['week'] = df_rei['date'].dt.strftime('%W').astype('uint8')
df_ret_df1 = df_rei.groupby(['retail_item', 'week'])['number_of_ads'].agg([max, min, 'mean']).stack().reset_index(level=[2]).rename(columns={'level_2': 'mm', 0: 'vals'}).reset_index()这是我需要做的第二个聚合,类似于第一个聚合,但我现在选择的是不同的列:
df_re['price_gap'] = df_re['high_price'] - df_re['low_price']
dff_rei1 = df_re.groupby(['date', 'retail_item']).agg({'price_gap': 'mean'})
dff_rei1 = dff_rei1.reset_index(level=[0,1])
dff_rei1['week'] = pd.DatetimeIndex(dff_rei1['date']).week
dff_rei1['year'] = pd.DatetimeIndex(dff_rei1['date']).year
dff_rei1['week'] = dff_rei1['date'].dt.strftime('%W').astype('uint8')
dff_ret_df2 = dff_rei1.groupby(['retail_item', 'week'])['price_gap'].agg([max, min, 'mean']).stack().reset_index(level=[2]).rename(columns={'level_2': 'mm', 0: 'vals'}).reset_index()现在,我在挣扎,如何将第一次、第二次聚合的输出合并成一个数据帧,以生成堆叠的线条图。这样做有可能吗?
目标
我想在它的y轴采用不同的列时,例如y轴应该显示#的广告和价格范围,而x轴显示52周的周期。这是我试图绘制的部分代码:
for g, d in df_ret_df1.groupby('retail_item'):
fig, ax = plt.subplots(figsize=(7, 4), dpi=144)
sns.lineplot(x='week', y='vals', hue='mm', data=d,alpha=.8)
y1 = d[d.mm == 'max']
y2 = d[d.mm == 'min']
plt.fill_between(x=y1.week, y1=y1.vals, y2=y2.vals)
for year in df['year'].unique():
data = df_rei[(df_rei.date.dt.year == year) & (df_rei.retail_item == g)]
sns.lineplot(x='week', y='price_gap', ci=None, data=data,label=year,alpha=.8)有什么好的方法吗?这样我们就可以构造绘图数据,在熊猫中可以很容易地在不同的列上进行数据聚合。还有别的办法可以让这一切发生吗?有什么想法吗?
期望输出
下面是我想要得到的期望输出:
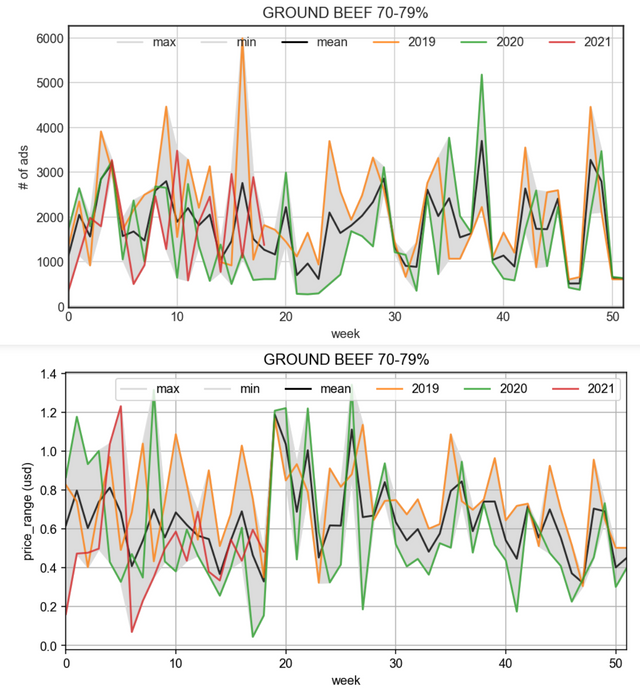
我应该如何绘制数据才能像这样得到我想要的情节呢?有什么想法吗?
回答 1
Stack Overflow用户
发布于 2021-05-11 15:50:39
熊猫群的特性是非常通用的,您可以大大减少代码行,以实现最终的绘图数据。
plotdf = df_re.groupby([ 'retail_item',df_re['date'].dt.year,df_re['date'].dt.week]).agg({'number_of_ads':'sum','price_gap':'mean'}).unstack().T一旦您以正确的方式完成了聚合,就使用for循环来显示在不同的图中所需的每个度量。通过使用熊猫描述特征来计算飞行中的最小和最大值,绘制出一个阴影范围:
f,axs = plt.subplots(2,1,figsize=(20,14))
axs=axs.ravel()
for i,x in enumerate(['number_of_ads','price_gap']):
plotdf.loc[x].plot(rot=90,grid=True,ax=axs[i])
plotdf.loc[x].T.describe().T[['min','max']].plot(kind='area',color=['w','grey'],alpha=0.3,ax=axs[i],title= x)
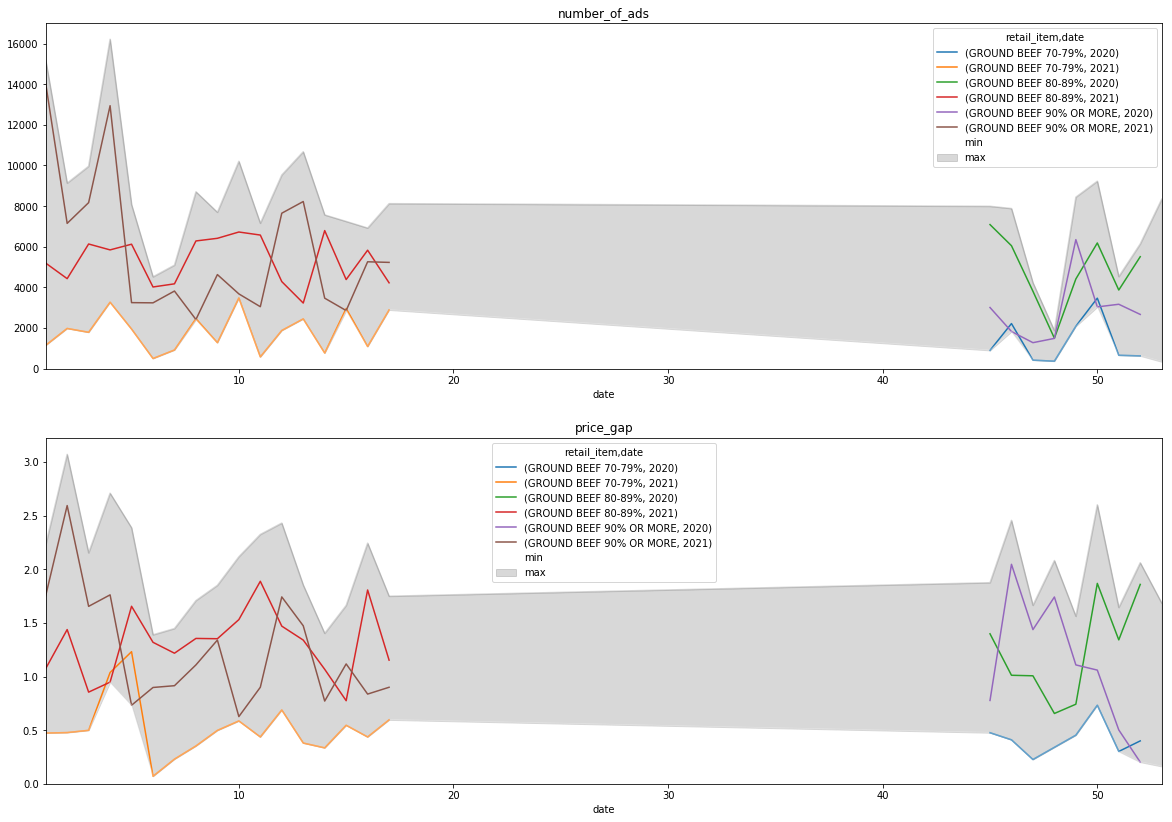
用更新的代码编辑:
plotdf = df_re.groupby(['retail_item',df_re['date'].dt.year,df_re['date'].dt.week]).agg({'number_of_ads':'sum','weighted_avg':'mean'}).unstack().T
f,axs = plt.subplots(3,2,figsize=(20,14))
axs=axs.ravel()
i=0
for col in plotdf.columns.get_level_values(0).unique():
for x in ['number_of_ads','weighted_avg']:
plotdf.loc[x,col].plot(rot=90,grid=True,ax=axs[i]);
plotdf.loc[x,col].T.describe().T[['min','max']].plot(kind='area',color=['w','grey'],alpha=0.3,ax=axs[i],title= col+', '+x)
i+=1https://stackoverflow.com/questions/67438164
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号