
在两个单独的数据中查找匹配的r函数?
我在R程序中是新的,所以我搜索了很多,但找不到我想要的东西。
我有两张数据,就像;
数据1:
Accession `Gene Symbol` `siCON-1` `siCON-2` `siCON-3` `siTR-1` `siTR-2` `siTR-3` `log2(siTR/s~ p_val `-log10(t.test si~
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Q14258 TRIM25 2283. 2570. 2749. 489 498. 480. -2.37 1.14e-4 3.94
2 Q9P035 PTPLAD1; HACD3 1080. 857. 1060. 338. 439. 264 -1.52 1.74e-3 2.76
3 Q9NP99 TREM1 45.7 NA 65.3 55 32.7 3.2 -0.873 3.10e-1 0.508
4 P35226 BMI1; COMMD3-~ 46.3 42.6 36.1 12.3 23.7 12.6 -1.36 6.03e-3 2.22
5 Q14117 DPYS 44.9 NA 73.1 51.7 36.9 0.8 -0.985 2.79e-1 0.554
6 Q6IAN0 DHRS7B 173. 149. 213. 92.3 73.7 62.6 -1.22 7.77e-3 2.11 数据2:
V1 V2 V3 V4 V5 V6
1 A0A075B6P5 R-HSA-109582 https://reactome.org/PathwayBrowser/#/R-HSA-109582 Hemostasis TAS Homo sapiens
2 A0A075B6P5 R-HSA-1280218 https://reactome.org/PathwayBrowser/#/R-HSA-1280218 Adaptive Immune System TAS Homo sapiens
3 A0A075B6P5 R-HSA-1280218 https://reactome.org/PathwayBrowser/#/R-HSA-1280218 Adaptive Immune System IEA Homo sapiens
4 A0A075B6P5 R-HSA-1643685 https://reactome.org/PathwayBrowser/#/R-HSA-1643685 Disease TAS Homo sapiens
5 A0A075B6P5 R-HSA-1643685 https://reactome.org/PathwayBrowser/#/R-HSA-1643685 Disease IEA Homo sapiens
6 A0A075B6P5 R-HSA-166658 https://reactome.org/PathwayBrowser/#/R-HSA-166658 Complement cascade TAS Homo sapiens我只想从表2的表1中搜索每个登录ID,如果匹配,我想将表2中的V2和V4复制到表1中。
我该怎么做?提前谢谢。
编辑:不好意思混淆了,加入是匹配的,V1是第二数据的匹配。
我想把“Q14258”作为一个例子,从第一个dataframe到第二个dataframe V1,如果有匹配的话,我想从第二个dataframe获取V2和V4,并在dataframe 1中添加新的列。我希望这样可以清除它。
Edit2:我使用了这段代码
matches <- match(dataframe1$Accession,dataframe2$V1)
我可以找到地点,但后来我坚持了下来。
[1] 87059 130058 126612 50691 86417 97429 80338 NA NA 34876 132613 138390 86681 48874 NA NA NA 121653 NA
[20] 83210 NA NA 22832 98354 104386 80531 11963 338 NA 58060 50032 12127 133036 11434 111307 26229 NA 89105
[39] 107669 2329 57826 NA 12101 35659 NA 100915 NA 119519 NA NA 92556 128938 13341 130104 133727 103605 NA
[58] 105145 124370 27343 NA 100357 47092 93135 39138 66942 NA 23662 116234 NA 85757 NA 125647 NA NA NA
[77] 59705 NA 109960 44700 135309 121942 NA 74508 NA NA 111882 15365 94138 122808 137613 58407 28641 NA 110505
[96] 76572 NA 104295 NA 130022 71937 63190 101249 113658 133776 36281 NA 61907 56843 NA 94265 24763 119085 81442
[115] NA NA 89343 NA NA 100597 NA 4782 131283 88704 NA NA 67450 57507 118512 10851 NA 12182 58482回答 1
Stack Overflow用户
发布于 2021-05-24 15:40:33
当您想要组合两个数据文件时,就需要使用一个join。
我做了一些例子数据,因为我不确定我是否理解你的数据在问题中。我知道Accession在df1中和V1在df2中是一样的。
library(tidyverse)
df1 <- tribble(
~Accession, ~GeneSymbol,
'Q1', 'TRIM25',
'Q2', 'PTPLAD1',
'Q3', 'TREM1' )
df2 <- tribble(
~V1, ~V2,
'Q1', 'R-HSA-109581',
'Q2', 'R-HSA-109582',
'Q4', 'R-HSA-109583',
'Q5', 'R-HSA-109584',
'Q6', 'R-HSA-109585' )
)如何进行连接取决于您想要什么。对于inner_join(),结果包含df1和df2中的键(Accession)。
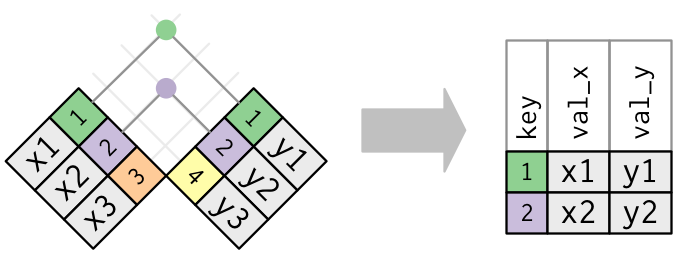
df1 %>%
inner_join(df2, by=c("Accession" = "V1"))加入GeneSymbol V2 1 Q1 TRIM25 R-HSA-109581 2 Q2 PTPLAD1 R-HSA-109582
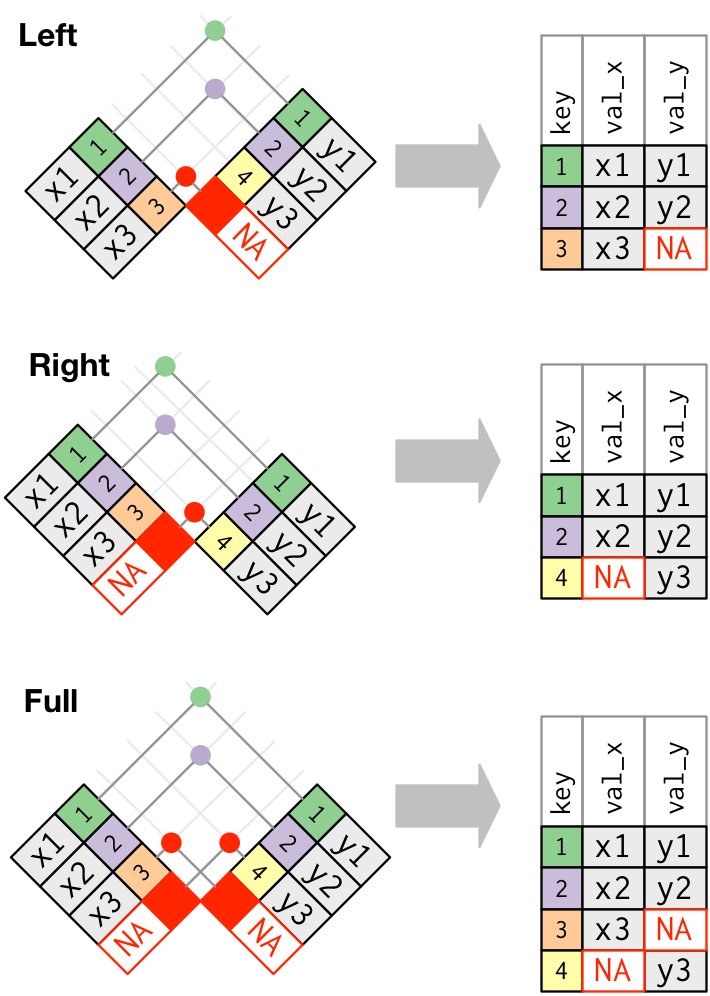
left_join()将所有键保存在df1 (Accession)中,并从具有匹配键的df2中添加列。它将NA作为df1中键的新列,而在df2中没有匹配。
df1 %>%
left_join(df2, by=c("Accession" = "V1"))加入GeneSymbol V2 1 Q1 TRIM25 R-HSA-109581 2 Q2 PTPLAD1 R-HSA-109582 3 Q3 TREM1 NA
还有其他类型的连接。查看哈德利韦翰( Hadley Wickham)书中的信息。
https://stackoverflow.com/questions/67672107
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号