
基于布尔条件的范畴分配
基于布尔条件的范畴分配
提问于 2021-05-25 12:21:48
我试图找出是否有更好的方法根据条件对数据进行分类。
示例数据:查看所识别的地方是否具有物理、社会和/或经济角色。如果有任何/多个角色存在,该位置将标记为"1“。
import pandas as pd
df = pd.DataFrame([[0, 1, 0], [0, 1, 1], [0, 1, 0], [0, 0, 1], [1,1,1], [1,1,0], columns=["PHYSICAL", "SOCIAL", "ECONOMIC"])数据
| | PHYSICAL | SOCIAL | ECONOMIC |
| - | -------- | ------ | -------- |
| 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 1 |
| 2 | 0 | 1 | 0 |
| 3 | 0 | 0 | 1 |
| 4 | 1 | 1 | 1 |
| 5 | 1 | 1 | 0 | 我想知道的:如何创建一个新列,根据True/False值为每一行分配一个类别。
所有可能的类别:
- 物质(仅)
- 社会(仅)
- 经济(仅)
- 物质与社会
- 物理与经济
- 社会经济
- 物质、社会和经济(全部)
预期结果
| | PHYSICAL | SOCIAL | ECONOMIC | CATEGORY |
| - | -------- | ------ | -------- | --------------- |
| 0 | 0 | 1 | 0 | social |
| 1 | 0 | 1 | 1 | social_economic |
| 2 | 0 | 1 | 0 | social |
| 3 | 0 | 0 | 1 | economic |
| 4 | 1 | 1 | 1 | all_cat |
| 5 | 1 | 1 | 0 | physical_social |我尝试过的:
df['CATEGORY'] = np.where(df['PHYSICAL'], np.where(df['SOCIAL'],
np.where(df['ECONOMIC'], 'All', 'FALSE'), 'FALSE'), 'FALSE')谢谢!
回答 3
Stack Overflow用户
回答已采纳
发布于 2021-05-25 12:36:31
你可以使用df.dot
df['CATEGORY'] = df.dot(df.columns + '_').str.rstrip('_').str.lower()输出:
PHYSICAL SOCIAL ECONOMIC CATEGORY
0 0 1 0 social
1 0 1 1 social_economic
2 0 1 0 social
3 0 0 1 economic
4 1 1 1 physical_social_economic
5 1 1 0 physical_socialStack Overflow用户
发布于 2021-05-25 12:48:51
也许你也可以试试这个解决方案
import pandas as pd
df = pd.DataFrame([[0, 1, 0], [0, 1, 1], [0, 1, 0], [0, 0, 1], [1,1,1], [1,1,0]], columns=["PHYSICAL", "SOCIAL", "ECONOMIC"])
def get_category(physical,social,economic):
if physical ==1 and social ==1 and economic ==1:
return 'all_cat'
elif physical ==0 and social ==0 and economic ==0:
return 'None'
elif physical == 1 and social == 1 and economic == 0:
return 'physical_social'
elif physical == 1 and social == 0 and economic == 1:
return 'physical_economic'
elif physical == 0 and social == 1 and economic == 1:
return 'social_economic'
elif physical ==1:
return 'physical'
elif social == 1:
return 'social'
elif economic == 1:
return 'economic'
df['category'] = df.apply(lambda x:get_category(x['PHYSICAL'],x['SOCIAL'],x['ECONOMIC']),axis=1)
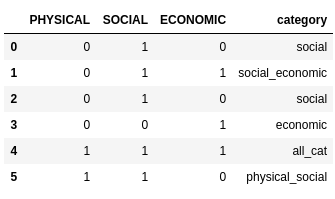
Stack Overflow用户
发布于 2021-05-25 12:45:18
这是否理想的结果?如果你不介意的话,这是一种很残忍的方法。
df['CATEGORY'] = ''
for col_name in df.columns:
df.ix[df[col_name]==1, 'CATEGORY'] = df['CATEGORY'] + '_' + col_name
df['CATEGORY'] = df['CATEGORY'].apply(lambda x: x.lower().strip('_'))
df输出
PHYSICAL SOCIAL ECONOMIC CATEGORY
0 0 1 0 social
1 0 1 1 social_economic
2 0 1 0 social
3 0 0 1 economic
4 1 1 1 physical_social_economic
5 1 1 0 physical_social页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67687814
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号