
立即用臂内装GCC组件加载16位(或更大)
注意:为了简洁起见,这里的示例是简化的,所以它们不能证明我的意图是正确的。如果我只是写到一个与示例完全一样的内存位置,那么就会是最好的C。然而,我在做一些我不能在这个例子中使用C的事情,即使在通常情况下最好还是呆在C中。
我试图用值加载寄存器,但我仍然坚持使用8位的即时性。
我的代码:
https://godbolt.org/z/8EE45Gerd
#include <cstdint>
void a(uint32_t value) {
*(volatile uint32_t *)(0x21014) = value;
}
void b(uint32_t value) {
asm (
"push ip \n\t"
"mov ip, %[gpio_out_addr_high] \n\t"
"lsl ip, ip, #8 \n\t"
"add ip, %[gpio_out_addr_low] \n\t"
"lsl ip, ip, #2 \n\t"
"str %[value], [ip] \n\t"
"pop ip \n\t"
:
: [gpio_out_addr_low] "I"((0x21014 >> 2) & 0xff),
[gpio_out_addr_high] "I"((0x21014 >> (2+8)) & 0xff),
[value] "r"(value)
);
}
// adding -march=ARMv7E-M will not allow 16-bit immediate
// void c(uint32_t value) {
// asm (
// "mov ip, %[gpio_out_addr] \n\t"
// "str %[value], [ip] \n\t"
// :
// : [gpio_out_addr] "I"(0x1014),
// [value] "r"(value)
// );
// }
int main() {
a(20);
b(20);
return 0;
}当我编写一个C代码(请参阅a())时,它将被组装到Godbolt中:
a(unsigned char):
mov r3, #135168
str r0, [r3, #20]
bx lr我认为它使用MOV作为伪指令。当我想在程序集中做同样的事情时,我可以将这个值放入某个内存位置并用LDR加载它。我认为,当我使用- many =arMv7E-M(用MOV替换为LDR)时,C代码就是这样组装的,但是在许多情况下,这对我来说是不切实际的,因为我将用它来做其他事情。
在0x21014地址的情况下,前2位是零,所以当我正确地移动这个18位数时,我可以把它当作16位,这就是我在b()中所做的,但是我仍然必须用8位直接传递它。然而,在Keil文档中,我注意到提到了16位即时性:
https://www.keil.com/support/man/docs/armasm/armasm_dom1359731146992.htm
https://www.keil.com/support/man/docs/armasm/armasm_dom1361289878994.htm
在ARMv6T2和更高版本的ARM和拇指指令集中包括:
可以将0x00000000至0x0000FFFF范围内的任何值加载到寄存器中的MOV指令。一种MOVT指令,它可以将0x0000到0xFFFF范围内的任何值加载到寄存器的最重要部分,而不需要更改。
最不重要的一半的内容。
我认为我的CortexM4应该是ARMv7E-M,并且应该满足这个"ARMv6T2及以后“的要求,并且应该能够使用16位的即时性。
然而,从GCC的在线组装文档中,我没有看到这样的说法:
https://gcc.gnu.org/onlinedocs/gcc/Machine-Constraints.html
当我启用ARMv7E-M arch并取消注释使用常规"I“直接的c()时,我会得到一个编译错误:
<source>: In function 'void c(uint8_t)':
<source>:29:6: warning: asm operand 0 probably doesn't match constraints
29 | );
| ^
<source>:29:6: error: impossible constraint in 'asm'因此,我想知道是否有一种方法可以使用GCC内联程序集的16位即插即用,还是我遗漏了什么(这会使我的问题变得无关紧要)?
旁边的问题是,是否有可能使这些伪指令在“天栓”中失效?我已经看到它们与RISC-V程序集一起使用,但我更希望看到拆卸的真正字节码,以查看这些伪/宏程序集指令所产生的确切指令。
回答 1
Stack Overflow用户
发布于 2021-05-30 05:48:26
@Jester在注释中建议使用i约束传递更大的直接值,或者使用真实的C变量,用所需的值初始化它,并让内联程序集接受它。这听起来是最好的解决方案,在内联程序集上花费的时间越少越好,想要获得更好性能的人往往低估了C/C++工具链在给定正确代码时在优化方面的强大程度。对于许多人来说,重写C/C++代码是解决问题的方法,而不是重新处理程序集中的所有内容。@Peter Cordes提到不使用内联装配,我同意。然而,在这种情况下,某些指令的精确时间是非常关键的,我不能以稍微不同的方式来冒险工具链,优化一些指令的时间。
位敲击协议并不理想,在大多数情况下,解决方案是避免位敲击,但在我的例子中,并不是那么简单,其他方法也没有起作用:
当我需要推送更多信号和任意长度时,8-bit/16-bit.
- Tried
- SPI不能用来传输数据,而HW只支持使用DMA2GPIO,并且存在抖动问题。
- 尝试了IRQ处理程序,这占用了太多的开销,我的性能下降了(如下面所示,只有2个nops,所以在空闲时间没有太多的空间)。
- 尝试了比特预焙流(包括定时),然而,对于1字节的实际数据,我最终保存了64个字节的流数据,从内存中读取了大量的slower.
- Pre-backing函数,用于每个写值(并有一个函数查找表,用于每个值写入)工作得很好,实际上太快了,因为现在工具链有编译时已知的值,并且能够很好地优化它,我的TCK在40 my以上。问题是,我不得不增加很多延迟来减慢速度(8 8MHz),并且必须对每个输入值执行,当长度为8位或更少时,它是可以的,但是对于32位长度,不可能插入闪存(2^32 => 4294967296),并将单个32位访问连接到FPGA结构中的TCK signal.
- Implementing这个外围设备上,产生了很大的抖动,这将允许我控制一切,这通常是正确的答案,但是想尝试在一个没有结构的设备上实现这一点。
长话短说,比特撞击是不好的,而且大多数情况下有更好的方法来绕过它,而使用内联程序集的非参数化实际上可能会在不知情的情况下产生更糟的结果,但在我的例子中,我需要它。在我之前的代码中,我试图把注意力集中在一个关于直接性的简单问题上,而不是切线或X问题的讨论。
现在回到“将更大的直接传递到程序集”的主题,下面是一个更真实的例子的实现:
https://godbolt.org/z/5vbb7PPP5
#include <cstdint>
const uint8_t TCK = 2;
const uint8_t TMS = 3;
const uint8_t TDI = 4;
const uint8_t TDO = 5;
template<uint8_t number>
constexpr uint8_t powerOfTwo() {
static_assert(number <8, "Output would overflow, the JTAG pins are close to base of the register and you shouldn't need PIN8 or above anyway");
int ret = 1;
for (int i=0; i<number; i++) {
ret *= 2;
}
return ret;
}
template<uint8_t WHAT_SIGNAL>
__attribute__((optimize("-Ofast")))
uint32_t shiftAsm(const uint32_t length, uint32_t write_value) {
uint32_t addressWrite = 0x40021014; // ODR register of GPIO port E (normally not hardcoded, but just for godbolt example it's like this)
uint32_t addressRead = 0x40021010; // IDR register of GPIO port E (normally not hardcoded, but just for godbolt example it's like this)
uint32_t count = 0;
uint32_t shift_out = 0;
uint32_t shift_in = 0;
uint32_t ret_value = 0;
asm volatile (
"cpsid if \n\t" // Disable IRQ
"repeatForEachBit%=: \n\t"
// Low part of the TCK
"and.w %[shift_out], %[write_value], #1 \n\t" // shift_out = write_value & 1
"lsls %[shift_out], %[shift_out], %[write_shift] \n\t" // shift_out = shift_out << pin_shift
"str %[shift_out], [%[gpio_out_addr]] \n\t" // GPIO = shift_out
// On the first cycle this is redundant, as it processed the shift_in from the previous iteration.
// First iteration is safe to do extraneously as it's just doing zeros
"lsr %[shift_in], %[shift_in], %[read_shift] \n\t" // shift_in = shift_in >> TDI
"and.w %[shift_in], %[shift_in], #1 \n\t" // shift_in = shift_in & 1
"lsl %[ret_value], #1 \n\t" // ret = ret << 1
"orr.w %[ret_value], %[ret_value], %[shift_in] \n\t" // ret = ret | shift_in
// Prepare things that are needed toward the end of the loop, but can be done now
"orr.w %[shift_out], %[shift_out], %[clock_mask] \n\t" // shift_out = shift_out | (1 << TCK)
"lsr %[write_value], %[write_value], #1 \n\t" // write_value = write_value >> 1
"adds %[count], #1 \n\t" // count++
"cmp %[count], %[length] \n\t" // if (count != length) then ....
// High part of the TCK + sample
"str %[shift_out], [%[gpio_out_addr]] \n\t" // GPIO = shift_out
"nop \n\t"
"nop \n\t"
"ldr %[shift_in], [%[gpio_in_addr]] \n\t" // shift_in = GPIO
"bne.n repeatForEachBit%= \n\t" // if (count != length) then repeatForEachBit
"cpsie if \n\t" // Enable IRQ - the critical part finished
// Process the shift_in as normally it's done in the next iteration of the loop
"lsr %[shift_in], %[shift_in], %[read_shift] \n\t" // shift_in = shift_in >> TDI
"and.w %[shift_in], %[shift_in], #1 \n\t" // shift_in = shift_in & 1
"lsl %[ret_value], #1 \n\t" // ret = ret << 1
"orr.w %[ret_value], %[ret_value], %[shift_in] \n\t" // ret = ret | shift_in
// Outputs
: [ret_value] "+r"(ret_value),
[count] "+r"(count),
[shift_out] "+r"(shift_out),
[shift_in] "+r"(shift_in)
// Inputs
: [gpio_out_addr] "r"(addressWrite),
[gpio_in_addr] "r"(addressRead),
[length] "r"(length),
[write_value] "r"(write_value),
[write_shift] "M"(WHAT_SIGNAL),
[read_shift] "M"(TDO),
[clock_mask] "I"(powerOfTwo<TCK>())
// Clobbers
: "memory"
);
return ret_value;
}
int main() {
shiftAsm<TMS>(7, 0xff); // reset the target TAP controler
shiftAsm<TMS>(3, 0x12); // go to state some arbitary TAP state
shiftAsm<TDI>(32, 0xdeadbeef); // write to target
auto ret = shiftAsm<TDI>(16, 0x0000); // read from the target
return 0;
}@David关于减少程序集的评论将为工具链提供更多的机会来进一步优化“将地址加载到寄存器”,如果内联,则不应该再次加载地址(因此它们只完成一次读/写的多次调用)。这里启用了内联:
https://godbolt.org/z/K8GYYqrbq
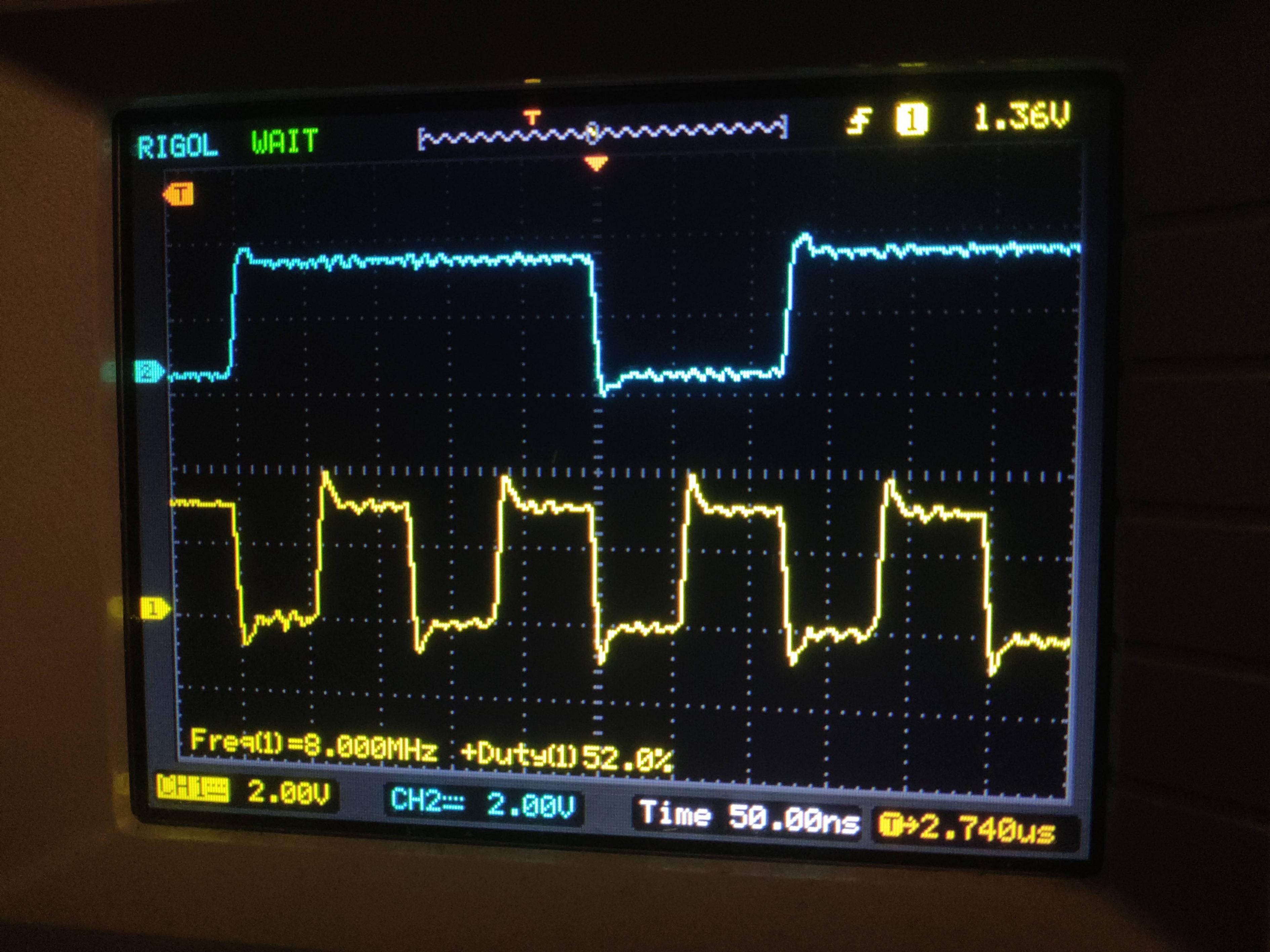
问题是,值得吗?我认为是的,我的TCK是死区8兆赫,我的占空比接近50%,而我对工作周期保持不变更有信心。抽样是在我期待它完成的时候完成的,不用担心它会因不同的工具链设置而得到不同的优化。
https://stackoverflow.com/questions/67756608
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号