
对年度数据每小时进行操作的最优Pythonic数据裁剪方法
对年度数据每小时进行操作的最优Pythonic数据裁剪方法
提问于 2021-05-31 04:34:23
我有一天的数据如下:
df =
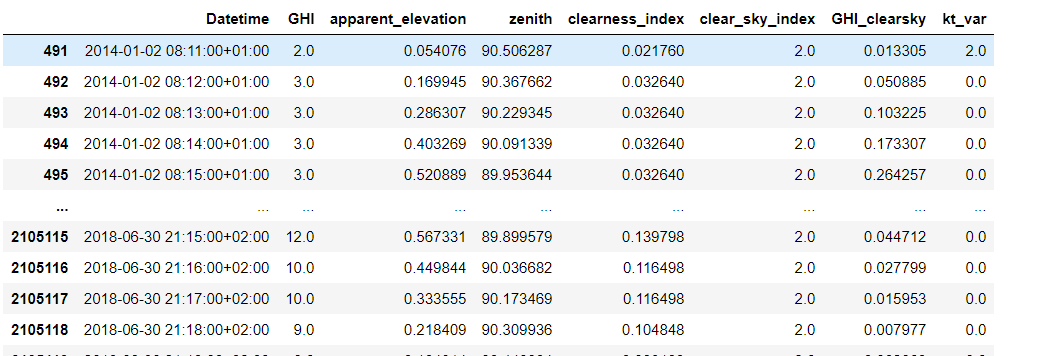
我的输出应该是这样的:
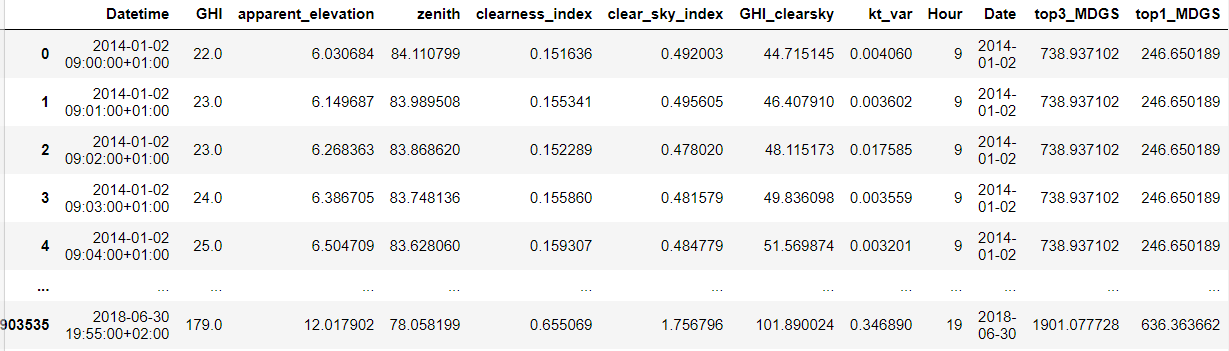
我需要做两项主要工作:
(A)创造千年发展目标:
- (GHI_clearsky-GHI),并将其保存到熊猫系列对象
- I中,然后按降序排序这个系列,df‘top3_ sum’中的
- 保存了df‘top1_MDGS中
- 的最高3值之和,保存了该系列的最大值
G 211
( b)过滤:
- ,我每天一小时一个小时地去,只在有60个读数的小时数据中选择分钟,而df‘’GHI‘值如果通过上述条件,则为非-zero
- ,我只保存这些结果以供进一步分析,否则就会丢弃。
我使用的代码如下所示:
def zenith_clipping_MDGS(df):
data_file = df
df_zenith_clipped = data_file[data_file.zenith<=86.273]
df_zenith_clipped.reset_index(drop = True, inplace = True)
df_zenith_clipped['Hour'] = df_zenith_clipped['Datetime'].dt.hour
df_zenith_clipped['Date'] = df_zenith_clipped['Datetime'].dt.date
adj_df = pd.DataFrame()
for date in df_zenith_clipped.Date.unique():
print(date)
df = df_zenith_clipped[df_zenith_clipped.Date == date]
MDGS = abs(df.GHI_clearsky - df.GHI)
MDGS = MDGS.sort_values(ascending = False)
MDGS.reset_index(inplace = True, drop=True)
df['top3_MDGS'] = sum(MDGS[:3])
df['top1_MDGS'] = MDGS[0]
for hour in df.Hour.unique():
df1 = df[df.Hour == hour]
if (len(df1) == 60) and (df1.GHI.any() != 0):
adj_df = adj_df.append(df1)
else:
continue
adj_df.reset_index(inplace = True, drop=True)
return adj_df这实际上比它应该花的时间更长。有没有什么功能,或者更好的方法去做这件事?
谢谢,谢谢你的反馈
回答 1
Stack Overflow用户
发布于 2021-05-31 05:30:43
一些可能被优化的东西..。
如果您只需要本系列中的前3个值,那么对这些值的整个列表进行排序可能不是很有效,因为额外的操作将被用于冗余排序。this question的答案讨论了一些更有效的方法(例如,使用max()查找最高值,将其从列表中删除,并重复3次)。
( b)虽然我并不完全熟悉您正在使用的数据/框架,但看起来您可能能够优化小时查找--特别是使用df1 = df[df.Hour == hour],==似乎需要遍历df.Hour中的所有内容,以便找到一个匹配的元素。如果可以重写为使用数字索引而不需要搜索,它可能执行得更快。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67767958
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号