
R: read.fwf将整数定义为数字
我有一个.txt文件,并且正在使用Rstudio。
200416657210340 1665721 20040608 20090930 20060910 20070910 20080827 20090804
200416657210345 1665721 20040907 20090203 20070331 20080719
200416657210347 1665721 20040914 20091026 20070213 20080114 20090302
200416657210352 1665721 20041111 20100315 20070123 20071205 20081202我正在尝试使用.txt读取read.fwf文件:
gripalisti <- read.fwf(file = "gripalisti.txt",
widths = c(15,8,9,9,9,9,9,9),
header = FALSE,
#stringsAsFactors = FALSE,
col.names = c("einst","bu","faeding","forgun","burdur1",
"burdur2","burdur3","burdur4"))这工作和列是正确的长度。然而,"einst“和"bu”应该是整数值,其余的应该是日期。
当导入第一列(ID变量)中的所有值时,如下所示:
2.003140e+14我一直在寻找一种将导入的列更改为整数(或字符?)的方法。值,我没有发现任何不会导致错误的东西。举个例子,我在google之后尝试过:
gripalisti <- read.fwf(file = "gripalisti.txt",
widths = c(15,8,9,9,9,9,9,9),
header = FALSE,
#stringsAsFactors = FALSE,
col.names = c("einst","bu","faeding","forgun","burdur1",
"burdur2","burdur3","burdur4"),
colclasses = c("integer", "integer", "Date", "Date",
"Date", "Date", "Date", "Date"))结果出现错误:
Error in read.table(file = FILE, header = header, sep = sep, row.names = row.names, :
unused argument (colclasses = c("integer", "integer", "Date", "Date", "Date", "Date", "Date", "Date"))dataset中有许多缺失值,超过100.000行。所以其他的进口方式对我来说没有用。数据集不是以制表符分隔的。
抱歉,如果这是显而易见的,我是一个非常新的R用户。
编辑:
谢谢你的帮助,我把它改成:
colClasses = c("character", 现在看上去不错。
回答 2
Stack Overflow用户
发布于 2021-05-30 18:37:15
正如评论中所建议的:
第一个字段不能作为"character";
- (additionally)存储为
"integer",它必须是"numeric"或
,如果日期不是%Y-%m-%d的默认格式,则需要在读取数据后转换它们。H 212G 213
准备:
writeLines("200416657210340 1665721 20040608 20090930 20060910 20070910 20080827 20090804\n200416657210345 1665721 20040907 20090203 20070331 20080719 \n200416657210347 1665721 20040914 20091026 20070213 20080114 20090302 \n200416657210352 1665721 20041111 20100315 20070123 20071205 20081202",
con = "gripalisti.txt")处决:
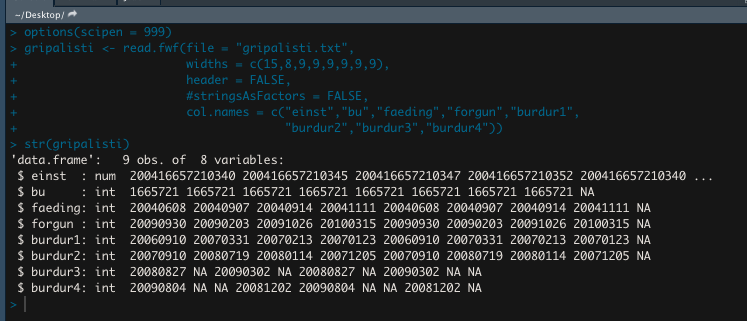
dat <- read.fwf("gripalisti.txt", widths = c(15,8,9,9,9,9,9,9), header = FALSE,
col.names = c("einst","bu","faeding","forgun","burdur1", "burdur2","burdur3","burdur4"),
colClasses = c("character", "integer", "character", "character", "character", "character", "character", "character"))
str(dat)
# 'data.frame': 4 obs. of 8 variables:
# $ einst : chr "200416657210340" "200416657210345" "200416657210347" "200416657210352"
# $ bu : int 1665721 1665721 1665721 1665721
# $ faeding: chr " 20040608" " 20040907" " 20040914" " 20041111"
# $ forgun : chr " 20090930" " 20090203" " 20091026" " 20100315"
# $ burdur1: chr " 20060910" " 20070331" " 20070213" " 20070123"
# $ burdur2: chr " 20070910" " 20080719" " 20080114" " 20071205"
# $ burdur3: chr " 20080827" " " " 20090302" " "
# $ burdur4: chr " 20090804" " " " " " 20081202"
dat[,3:8] <- lapply(dat[,3:8], as.Date, format = "%Y%m%d")
dat
# einst bu faeding forgun burdur1 burdur2 burdur3 burdur4
# 1 200416657210340 1665721 2004-06-08 2009-09-30 2006-09-10 2007-09-10 2008-08-27 2009-08-04
# 2 200416657210345 1665721 2004-09-07 2009-02-03 2007-03-31 2008-07-19 <NA> <NA>
# 3 200416657210347 1665721 2004-09-14 2009-10-26 2007-02-13 2008-01-14 2009-03-02 <NA>
# 4 200416657210352 1665721 2004-11-11 2010-03-15 2007-01-23 2007-12-05 <NA> 2008-12-02
str(dat)
# 'data.frame': 4 obs. of 8 variables:
# $ einst : chr "200416657210340" "200416657210345" "200416657210347" "200416657210352"
# $ bu : int 1665721 1665721 1665721 1665721
# $ faeding: Date, format: "2004-06-08" "2004-09-07" "2004-09-14" "2004-11-11"
# $ forgun : Date, format: "2009-09-30" "2009-02-03" "2009-10-26" "2010-03-15"
# $ burdur1: Date, format: "2006-09-10" "2007-03-31" "2007-02-13" "2007-01-23"
# $ burdur2: Date, format: "2007-09-10" "2008-07-19" "2008-01-14" "2007-12-05"
# $ burdur3: Date, format: "2008-08-27" NA "2009-03-02" NA
# $ burdur4: Date, format: "2009-08-04" NA NA "2008-12-02"Stack Overflow用户
发布于 2021-05-30 17:56:07
在这里,第一列中的数字是非常大的数字,如果以整数或数字的形式导入它,它将自动以指数格式显示。解决这个问题的方法是在读取文件之前设置“枕”。使用以下代码:
选项(scipen= 999)
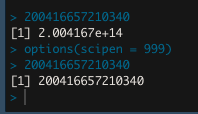
我觉得这应该能解决你的问题。
下面是我运行的代码,当然是您需要使用的日期列的代码。为此,您可以使用像as.Date这样的简单命令(gripalisti$burdur1,format = "%Y%m%d")
https://stackoverflow.com/questions/67764139
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号