
Distributions.jl分布的中心可信和最高后验密度区间的计算与绘制
我想(i)计算和(ii)绘制中心可信区间和最高后验密度区间,以便在Distributions.jl库中进行分布。理想情况下,我们可以编写自己的函数来计算CI和HPD,然后使用Plots.jl绘制它们。然而,我发现实现非常棘手(免责声明:我是Julia的新手)。对于库/repo/repo,有什么建议可以让计算和绘图变得更容易吗?
上下文
using Plots, StatsPlots, LaTeXStrings
using Distributions
dist = Beta(10, 10)
plot(dist) # thanks to StatsPlots it nicely plots the distribution
# missing piece 1: compute CI and HPD
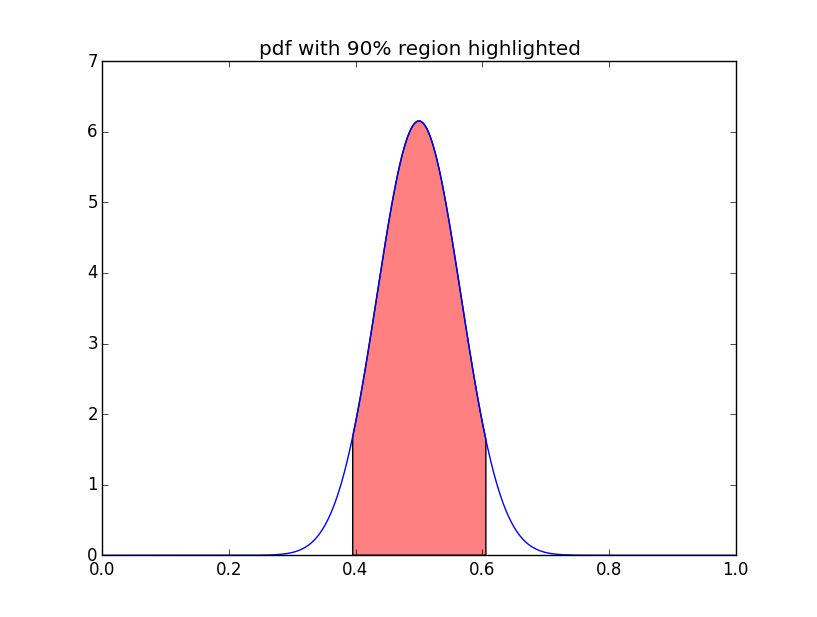
# missing piece 2: plot CI and HPD预期的最终结果总结在下图或在BDA3的第33页。
迄今发现的资源:
回答 3
Stack Overflow用户
发布于 2021-06-03 20:39:23
谢谢你更新这个问题,它带来了一个新的视角。
这个要点是正确的,只是它使用了朱莉娅的早期版本。因此,linspace应该被LinRange取代。使用using PyPlot代替using Plots。我会将绘图部分改为:
plot(cred_x, pdf(B, cred_x), fill=(0, 0.9, :orange))
plot!(x,pdf(B,x), title="pdf with 90% region highlighted")乍一看,CI的计算似乎是正确的。(就像封闭的类边界曲线的答案或问题的答案)。对于HDP来说,我同意封闭的类柠檬曲线。我只想说,您可以在gist代码上构建您的HDP函数。我还将有一个带有已知分布(如参考文档第33页,图2.2)的后验版本,因为您不需要进行示例。另一个样本像封闭的似柠檬状曲线。
Stack Overflow用户
发布于 2021-06-05 18:59:23
OP编辑了这个问题,所以我给出了一个新的答案。
对于中心可信区间,答案很简单:取每一点的分位数:
lowerBound = quantile(Normal(0, 1), .025)
upperBound = quantile(Normal(0, 1), .975)这将给出一个区间,在这个区间内,x的概率位于下界.025以下,对于上界也是如此,加起来就是.05。
HPDs更难计算。此外,它们往往不那么常见,因为它们具有一些不为中心可信区间所共享的奇怪属性。最简单的方法可能是使用蒙特卡罗算法。使用randomSample = rand(Normal(0, 1), 2^12)从正态分布中提取2^12样本。(或者,不管你想要多少样本,更多的样本都能给出更准确的结果,这些结果受到随机机会的影响更小。)然后,对于每个随机点,使用pdf.(randomSample)计算该随机点的概率密度。然后,选择95%的概率密度最高的点;将所有这些点都包含在最高密度区间,以及它们之间的任何点(我假设你处理的是像正态分布这样的单一分布)。
对于正态分布,有更好的方法可以做到这一点,但它们很难推广。
Stack Overflow用户
发布于 2021-06-04 01:20:05
您正在寻找ArviZ.jl,以及Turing.jl的MCMCChains。MCMCChains将为您提供非常基本的绘图功能,例如从每个链中估计的PDF图。ArviZ.jl ( Python ArviZ包的包装器)增加了更多的情节。
https://stackoverflow.com/questions/67825175
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号