
BeautifulSoup 4: AttributeError: NoneType没有属性find_next
项目:有关wordpress- plugins的元数据列表:-大约50个插件是感兴趣的!但挑战是:我想获取所有现有插件的元数据。之后,我想过滤掉的是那些具有最新时间戳的插件,这些插件是最近更新的(大多数)。这一切都是偶然的.所以最开始的基本网址是:
url = "https://wordpress.org/plugins/browse/popular/目标:我想获取我们在流行插件的前50页上找到的所有插件的元数据.例如.
https://wordpress.org/plugins/wp-job-manager
https://wordpress.org/plugins/ninja-forms
https://wordpress.org/plugins/participants-database ....and so on and so forth.我们开始:
import requests
from bs4 import BeautifulSoup
from concurrent.futures.thread import ThreadPoolExecutor
url = "https://wordpress.org/plugins/browse/popular/{}"
def main(url, num):
with requests.Session() as req:
print(f"Collecting Page# {num}")
r = req.get(url.format(num))
soup = BeautifulSoup(r.content, 'html.parser')
link = [item.get("href")
for item in soup.findAll("a", rel="bookmark")]
return set(link)
with ThreadPoolExecutor(max_workers=20) as executor:
futures = [executor.submit(main, url, num)
for num in [""]+[f"page/{x}/" for x in range(2, 50)]]
allin = []
for future in futures:
allin.extend(future.result())
def parser(url):
with requests.Session() as req:
print(f"Extracting {url}")
r = req.get(url)
soup = BeautifulSoup(r.content, 'html.parser')
target = [item.get_text(strip=True, separator=" ") for item in soup.find(
"h3", class_="screen-reader-text").find_next("ul").findAll("li")[:8]]
head = [soup.find("h1", class_="plugin-title").text]
new = [x for x in target if x.startswith(
("V", "Las", "Ac", "W", "T", "P"))]
return head + new
with ThreadPoolExecutor(max_workers=50) as executor1:
futures1 = [executor1.submit(parser, url) for url in allin]
for future in futures1:
print(future.result())那样运行--但是返回一些错误..(见下文)
Extracting https://wordpress.org/plugins/use-google-libraries/
Extracting https://wordpress.org/plugins/blocksy-companion/
Extracting https://wordpress.org/plugins/cherry-sidebars/
Extracting https://wordpress.org/plugins/accesspress-social-share/Extracting https://wordpress.org/plugins/goodbye-captcha/
Extracting https://wordpress.org/plugins/wp-whatsapp/在这里,错误的追溯:
Some characters could not be decoded, and were replaced with REPLACEMENT CHARACTER.
Traceback (most recent call last):
File "C:\Users\rob\.spyder-py3\dev\untitled0.py", line 51, in <module>
print(future.result())
File "C:\Users\rob\devel\IDE\lib\concurrent\futures\_base.py", line 432, in result
return self.__get_result()
File "C:\Users\rob\devel\IDE\lib\concurrent\futures\_base.py", line 388, in __get_result
raise self._exception
File "C:\Users\rob\devel\IDE\lib\concurrent\futures\thread.py", line 57, in run
result = self.fn(*self.args, **self.kwargs)
File "C:\Users\rob\.spyder-py3\dev\untitled0.py", line 39, in parser
target = [item.get_text(strip=True, separator=" ") for item in soup.find(
AttributeError: 'NoneType' object has no attribute 'find_next'Update:如上所述,我得到了这个AttributeError,它说NoneType没有属性find_next。下面是给我们带来棘手问题的底线。
target = [item.get_text(strip=True, separator=" ") for item in soup.find("h3", class_="screen-reader-text").find_next("ul").findAll("li")]具体来说,问题在soup.find()方法中,它可以返回一个标记(当它找到什么东西时),它有一个.find_next()方法(即属性),或者一个没有(当它找不到任何东西时),而不是。
tag = soup.find("h3", class_="screen-reader-text")
target = []
if tag:
lis = tag.find_next("ul").findAll("li")
target = [item.get_text(strip=True, separator=" ") for item in lis[:8]]顺便说一句,我们可以使用CSS选择器来运行:
target = [item.get_text(strip=True, separator=" ") for item in soup.select("h3.screen-reader-text + ul li")[:8]]这可以得到“ul下的所有li,它就在h3旁边,有屏幕阅读器-文本类”。如果我们希望li直接位于ul (通常它们通常都是,但其他元素并不总是这样),我们可以使用ul > li代替(>意思是“直接子”)。
注意:最好是将所有结果转储到csv文件中,或者-在屏幕上打印出来。
期待着收到你的来信
回答 2
Stack Overflow用户
发布于 2021-06-09 20:05:43
这一页组织得很好,所以刮起来应该是很直接的。您所需要做的就是得到插件卡,然后简单地提取必要的部分。
这是我对它的看法。
import time
import pandas as pd
import requests
from bs4 import BeautifulSoup
main_url = "https://wordpress.org/plugins/browse/popular"
headers = [
"Title", "Rating", "Rating Count", "Excerpt", "URL",
"Author", "Active installs", "Tested with", "Last Updated",
]
def wait_a_bit(wait_for: float = 1.5):
time.sleep(wait_for)
def parse_plugin_card(card) -> list:
title = card.select_one("h3").getText()
rating = card.select_one(
".plugin-rating .wporg-ratings"
)["data-rating"]
rating_count = card.select_one(
".plugin-rating .rating-count a"
).getText().replace(" total ratings", "")
excerpt = card.select_one(
".plugin-card .entry-excerpt p"
).getText()
plugin_author = card.select_one(
".plugin-card footer span.plugin-author"
).getText(strip=True)
active_installs = card.select_one(
".plugin-card footer span.active-installs"
).getText(strip=True)
tested_with = card.select_one(
".plugin-card footer span.tested-with"
).getText(strip=True)
last_updated = card.select_one(
".plugin-card footer span.last-updated"
).getText(strip=True)
plugin_url = card.select_one(
".plugin-card .entry-title a"
)["href"]
return [
title, rating, rating_count, excerpt, plugin_url,
plugin_author, active_installs, tested_with, last_updated,
]
with requests.Session() as connection:
pages = (
BeautifulSoup(
connection.get(main_url).text,
"lxml",
).select(".pagination .nav-links .page-numbers")
)[-2].getText(strip=True)
all_cards = []
for page in range(1, int(pages) + 1):
print(f"Scraping page {page} out of {pages}...")
# deal with the first page
page_link = f"{main_url}" if page == 1 else f"{main_url}/page/{page}"
plugin_cards = BeautifulSoup(
connection.get(page_link).text,
"lxml",
).select(".plugin-card")
for plugin_card in plugin_cards:
all_cards.append(parse_plugin_card(plugin_card))
wait_a_bit()
df = pd.DataFrame(all_cards, columns=headers)
df.to_csv("all_plugins.csv", index=False)它会抓取所有页面(目前共有49页),并将所有内容转储到.csv文件中,其中包含980行(截至目前),如下所示:
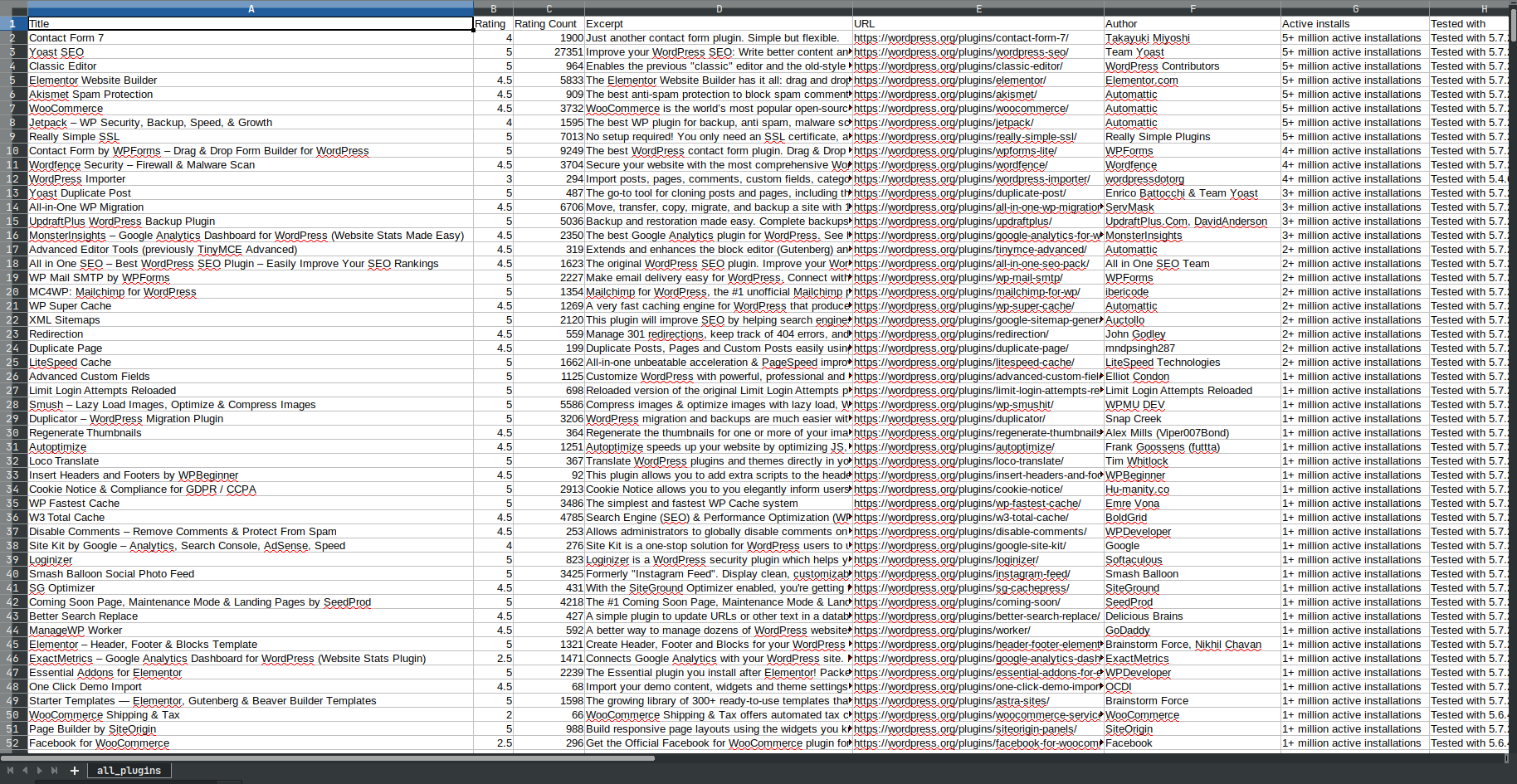
您甚至不必运行代码,整个转储都是这里。
Stack Overflow用户
发布于 2021-06-10 12:49:31
巴杜克的解决方案很棒,但只是想补充一下。
我们可以稍微修改插件卡的解析,因为有一个api可以重新处理所有的数据。仍然需要少量的处理(即。拿出作者的内容,评级存储在100,我相信(所以82的评级是82/100*5 = 4.1 -> "4星“),诸如此类的事情。
但我想我会和你分享。
import time
import pandas as pd
import requests
from bs4 import BeautifulSoup
main_url = "https://wordpress.org/plugins/browse/popular"
def wait_a_bit(wait_for: float = 1.5):
time.sleep(wait_for)
# MODIFICATION MADE HERE
def parse_plugin_card(card):
plugin_slug = card.select_one('a')['href'].split('/')[-2]
url = 'https://api.wordpress.org/plugins/info/1.0/%s.json' %plugin_slug
jsonData = requests.get(url).json()
sections = jsonData.pop('sections')
for k, v in sections.items():
sections[k] = BeautifulSoup(v).text
jsonData.update(sections)
return jsonData
with requests.Session() as connection:
pages = (
BeautifulSoup(
connection.get(main_url).text,
"lxml",
).select(".pagination .nav-links .page-numbers")
)[-2].getText(strip=True)
all_cards = []
for page in range(1, int(pages) + 1):
print(f"Scraping page {page} out of {pages}...")
# deal with the first page
page_link = f"{main_url}" if page == 1 else f"{main_url}/page/{page}"
plugin_cards = BeautifulSoup(
connection.get(page_link).text,
"lxml",
).select(".plugin-card")
for plugin_card in plugin_cards:
all_cards.append(parse_plugin_card(plugin_card))
wait_a_bit()
df = pd.DataFrame(all_cards)
df.to_csv("all_plugins.csv", index=False),这里是一个示例,向您展示列:
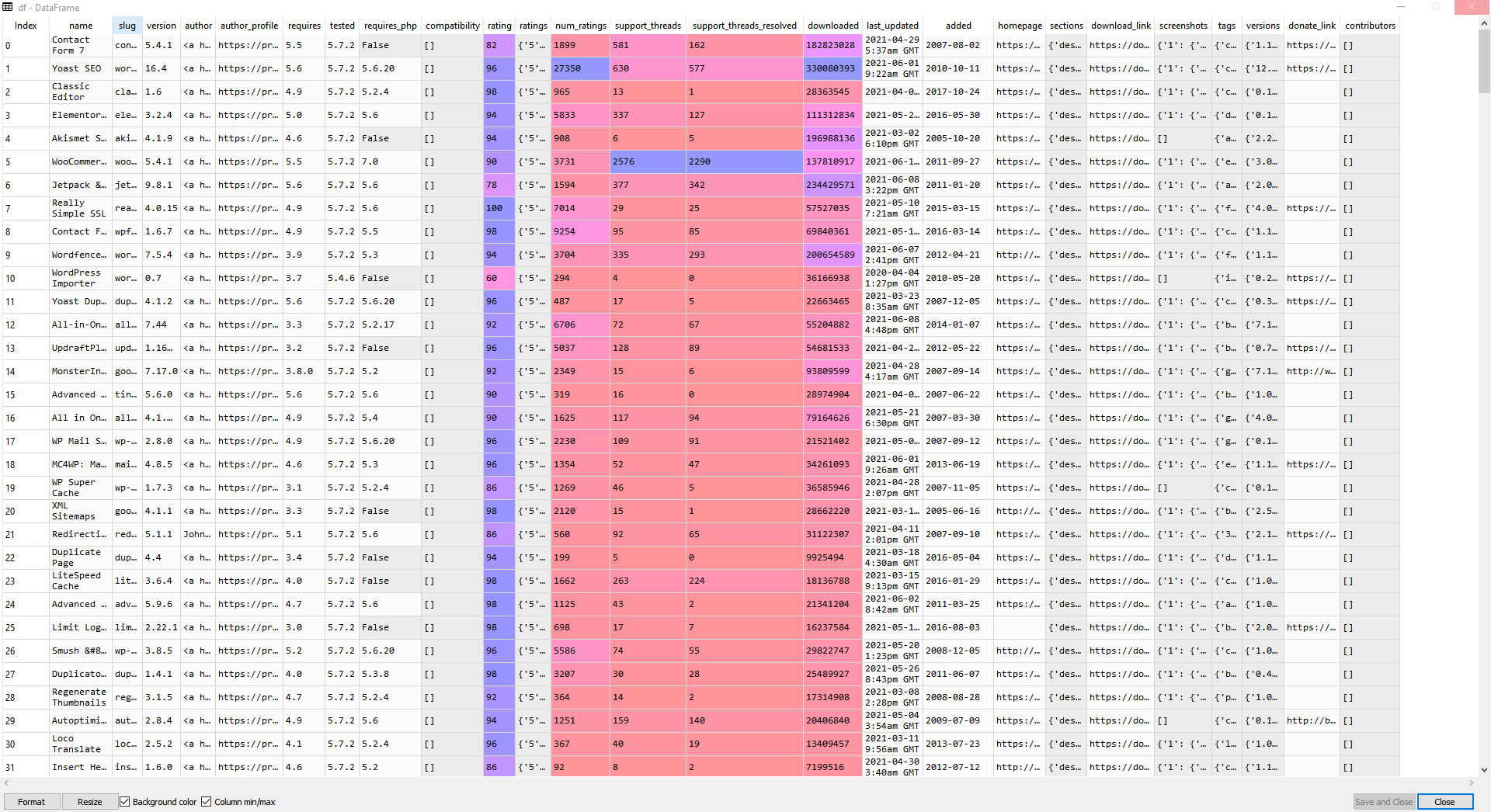
https://stackoverflow.com/questions/67872553
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号