
Vespa.ai利用多个实例来回答查询
我有带有多个容器/内容节点的Vespa.ai集群。在Vespa加载数据之后,我的应用程序发送查询并从Vespa获取数据。我想确保我很好地利用了所有的节点,并尽可能快地得到数据。我的应用程序构建HTTP请求并将其发送到其中一个节点。
我应该将请求定向到哪个节点/节点?如何确保所有实例都参与回答查询?
我应该如何利用所有集群节点?
Vespa知道如何将这些请求负载到其他实例以获得更好的性能吗?
回答 2
Stack Overflow用户
发布于 2021-06-23 07:56:42
Vespa是一个两层系统:
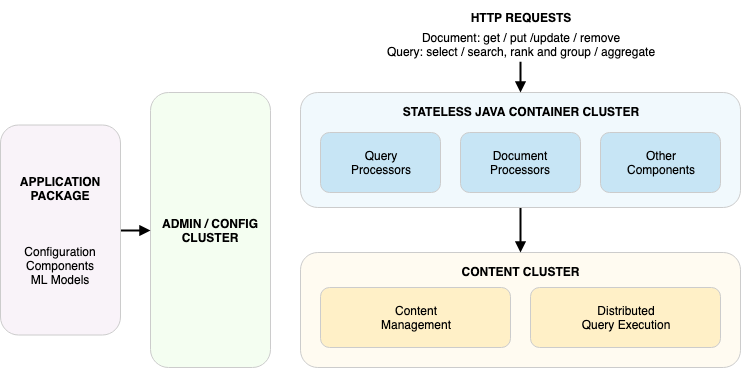
容器将在内容节点上负载平衡(如果您有多个组),但是由于您要将请求发送到容器,所以需要在这些容器上负载平衡。
这可以通过您在客户端编写的代码、VIP代码、您自己托管的另一层节点(例如Nginx )或托管负载均衡器(如AWS ELB )来实现。
Stack Overflow用户
发布于 2021-06-23 10:39:38
您可以通过将&presentation.timing=true&trace.timestamps&tracelevel=5添加到搜索请求来调试分布式查询执行,然后在响应中得到跟踪,在响应中可以看到查询是如何分派的,以及每个节点用于匹配查询所用的时间。也请参阅缩放Vespa https://docs.vespa.ai/en/performance/sizing-search.html
https://stackoverflow.com/questions/68095336
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号