
我想为MS Azure Synapse中存储为varchar(max)的匹配标记提取XML值。
我是新Azure,以前使用过SAS,现在我们移动到azure突触,在当前的环境中,我想提取存储在C列(varcharmax)中的XML标记值作为变量。数据集1: XML下面的https://i.stack.imgur.com/tbSIF.png保存在C列(PKDATA)中
{kind=link}
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<ns2:DataSet xmlns:ns2="http://www.test.com/t/cn/el">
<EnumObject>
<name>Inpatient</name>
<value>262784067</value>
<radiobutton>false</radiobutton>
</EnumObject>
<StringObject>
<name>xxx</name>
<prompt></prompt>
<value>/widget.jsp</value>
<width>99</width>
</StringObject>
</ns2:DataSet>如果名称是住院,那么262784067作为住院类型
输出
A
我使用以下代码选择a、b、pkdata.value('/EnumObject/name')作为dbo.extdata的住院类型
我得到以下错误,既找不到列"pkkddata“,也找不到用户定义的函数或聚合"pkdata.value",或者名称不明确。
我尝试使用以下查询,但给出了错误Msg 104220、级别16、状态1、第26行无法找到数据类型'xml‘。从.value交叉应用中选择a,b,(Pkdata) dbo.extdata (‘(/EnumObject/name/text()1’,'varchar(100)')作为x(pkdata)
当我使用以下代码时,只能在xml类型的列上调用XMLDT方法“节点”。我尝试使用以下方法,但在传递dbo.EXTDATA rt交叉连接xmltable( '/EnumObject/ name‘传递xmltype(rt.pkdata)列、名称编号路径'name/@value’)时,得到了错误的语法。
不知道该如何进行
Azure SQL版本Microsoft Azure SQL数据仓库- 10.0.16003.0 4月28日2021 04:55:16版权(c)微软公司
回答 1
Stack Overflow用户
发布于 2021-06-28 12:46:38
Azure Synapse Analytics,特别是专用的SQL池不支持XML数据类型或与其相关的任何函数,包括FOR XML、.nodes、.value、.query、.modify等。
如果需要这种类型的处理,可以使用传统的Server (如Server 2019 )或Azure SQL DB。一种选择是使用Synapse管道将数据移动到那里。作为另一种选择,您可以考虑使用Synapse笔记本和一些定制的Python / Scala / c#代码,但我对此只做了一个简单的测试。
Scala中的简单示例:
细胞1
// Get the table with the XML column from the database and expose as temp view
val df = spark.read.synapsesql("yourPool.dbo.someXMLTable")
df.createOrReplaceTempView("someXMLTable")细胞2
%%sql
-- Use SparkSQL to interrogate the XML
-- https://spark.apache.org/docs/2.3.0/api/sql/index.html#xpath
SELECT
colA,
colB,
xpath_string(pkData,'/DataSet/EnumObject[name="Inpatient"]/value') xvalue
FROM someXMLTable细胞3
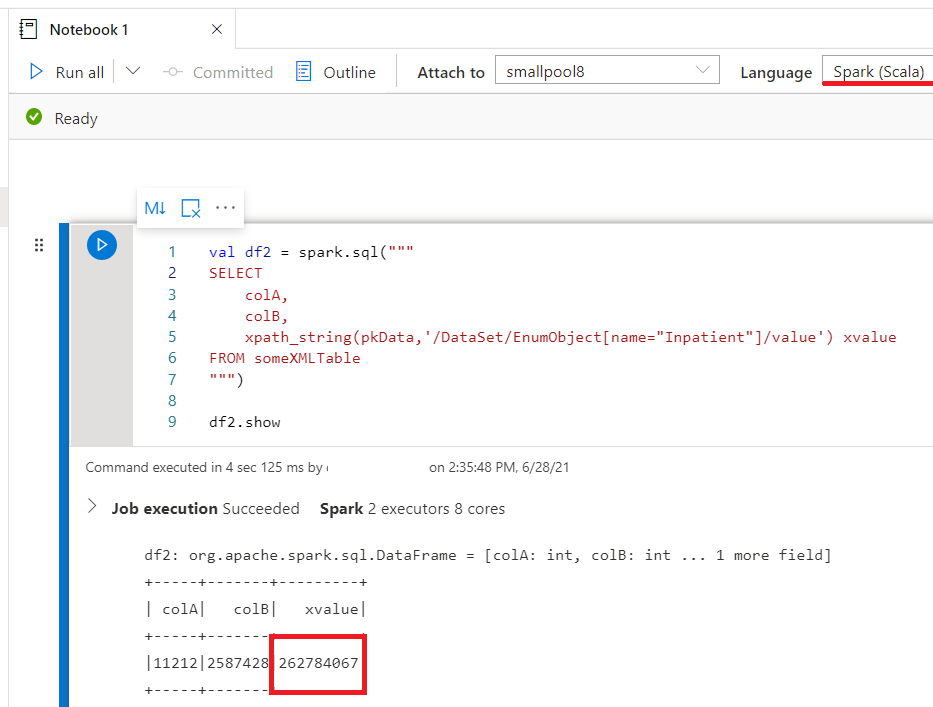
val df2 = spark.sql("""
SELECT
colA,
colB,
xpath_string(pkData,'/DataSet/EnumObject[name="Inpatient"]/value') xvalue
FROM someXMLTable
""")
df2.show细胞4
// Write that dataframe back to the dedicated SQL pool
df2.write.synapsesql("yourPool.dbo.someXMLTable_processed", Constants.INTERNAL)样本笔记本的屏幕打印:
XML现在有点过时了--您考虑过切换到JSON吗?另外,如果您的数据量不是那么大,那么只使用Azure SQL DB要比Synapse便宜得多。
https://stackoverflow.com/questions/68163457
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号