
基于协同过滤项的推荐系统精度
我想找个方法来知道我的推荐系统的准确性。我使用的方法是基于用户X电影矩阵(其中的内容是给定用户对给定电影的评分)创建一个KNN模型。基于这个模型,我有一个函数,我可以输入一个电影标题,它返回给我的K更类似的电影,我用来作为输入。有了这一点,我不知道如何衡量我的模型是否准确,以及所放映的电影是否真的与我用作输入的电影相似。有什么想法吗?
这里是我使用的数据集的一个示例
def create_sparse_matrix(df):
sparse_matrix = sparse.csr_matrix((df["rating"], (df["userId"], df["movieId"])))
return sparse_matrix
# getting the transpose - data_cf is the dataFrame name that I'm using
user_movie_matrix = create_sparse_matrix(data_cf).transpose() knn_cf = NearestNeighbors(n_neighbors=N_NEIGHBORS, algorithm='auto', metric='cosine')
knn_cf.fit(user_movie_matrix)# Creating function to get movies recommendations based in a movie input.
def get_recommendations_cf(movie_name, model):
# Getting the ID of the movie based on it's title
movieId = data_cf.loc[data_cf["title"] == movie_name]["movieId"].values[0]
distances, suggestions = model.kneighbors(user_movie_matrix.getrow(movieId).todense().tolist(), n_neighbors=10)
for i in range(0, len(distances.flatten())):
if(i == 0):
print('Recomendações para {0}: \n'.format(movie_name))
else:
print('{0}: {1}, com distância de {2}:'.format(i, data_cf.loc[data_cf["movieId"] == suggestions.flatten()[i]]["title"].values[0], distances.flatten()[i]))
return distances, suggestions调用推荐函数并显示每部电影推荐的的“距离”
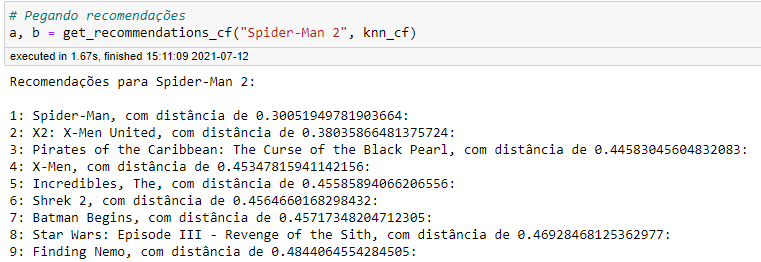
翻译:
蜘蛛人2:=对蜘蛛侠2的建议:
1:蜘蛛侠,com dist ncia de 0.30051949781903664= "1:蜘蛛侠,距离0.30051949781903664“
..。
9:找到尼莫,com dist ncia de 0.4844064554284505:“= "9:找到尼莫,距离为0.4844064554284505:”
回答 1
Stack Overflow用户
发布于 2021-07-16 14:25:34
当涉及到推荐系统时,衡量性能从来不是一项简单的任务。这是因为我们在一项建议中要寻找许多可取的特性:准确性、多样性、新颖性、.所有这些都可以用某种方式来衡量。有许多非常有用的文章在网络上涵盖了这个主题。我将链接几个具体处理精确性的引用:
- https://towardsdatascience.com/ranking-evaluation-metrics-for-recommender-systems-263d0a66ef54
- https://en.wikipedia.org/wiki/Evaluation_measures_(information_retrieval)
请记住,要进行任何类型的评估,您需要将数据分割成一组火车和一个测试集。在推荐系统中,由于所有用户和所有项目都必须在培训集和测试集中表示,所以必须使用分层方法。这意味着您应该为每个用户留出一定百分比的电影评论,而不是简单地抽样数据集的行。
https://stackoverflow.com/questions/68352569
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号