
在R中只将某些行从长到宽转换
在R中只将某些行从长到宽转换
提问于 2021-07-23 18:21:32
我有一个数据文件,开头是这样的:
schools <- structure(list(
school = c("Griffith Elementary", "Griffith Elementary", "Griffith Elementary", "Griffith Elementary", "Debs Elementary", "Debs Elementary", "Debs Elementary", "Debs Elementary", "Griffith Magnet Elementary", "Griffith Magnet Elementary", "Griffith Magnet Elementary", "Griffith Magnet Elementary"),
year = c(2016, 2017, 2018, 2019, 2016, 2017, 2018, 2019, 2016, 2017, 2018, 2019),
unique_id = c(25, 25, 25, 25, 14, 14, 14, 14, 25, 25, 25, 25),
enrollment = c(100, 105, 115, 110, 135, 140, 150, 145, 50, 50, 55, 55))) %>%
as.data.frame()看起来是这样:
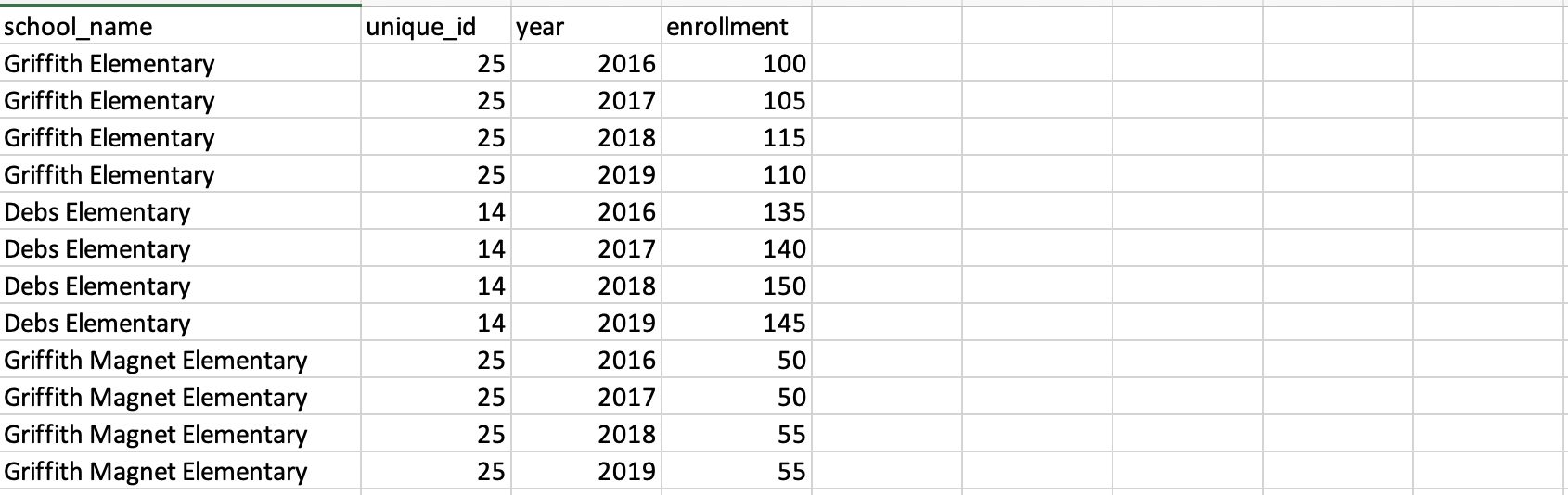
我想要做的是使用pivot_wider只转换具有相同唯一ID的行。
这个是可能的吗?任何帮助都可以。
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-07-23 18:30:36
当相邻的值不相似时,我们可以使用rleid从data.table在'unique_id‘列上生成不同的id,然后按'unique_id’分组,更改'new‘列以使用match创建顺序值,在进行pivot_wider重组为'wide’之前,用row_number()创建一个序列列来说明重复的元素。
library(dplyr)
library(data.table)
library(tidyr)
library(stringr)
schools %>%
mutate(new = rleid(unique_id)) %>%
group_by(unique_id) %>%
mutate(new = match(new, unique(new))) %>%
group_by(new) %>%
mutate(rn = row_number()) %>%
pivot_wider(names_from = new,
values_from = c(school, year, unique_id, enrollment), names_sep = "") %>%
select(-rn) %>%
select(order(rowid(str_remove(names(.), "\\d+"))))-ouptut
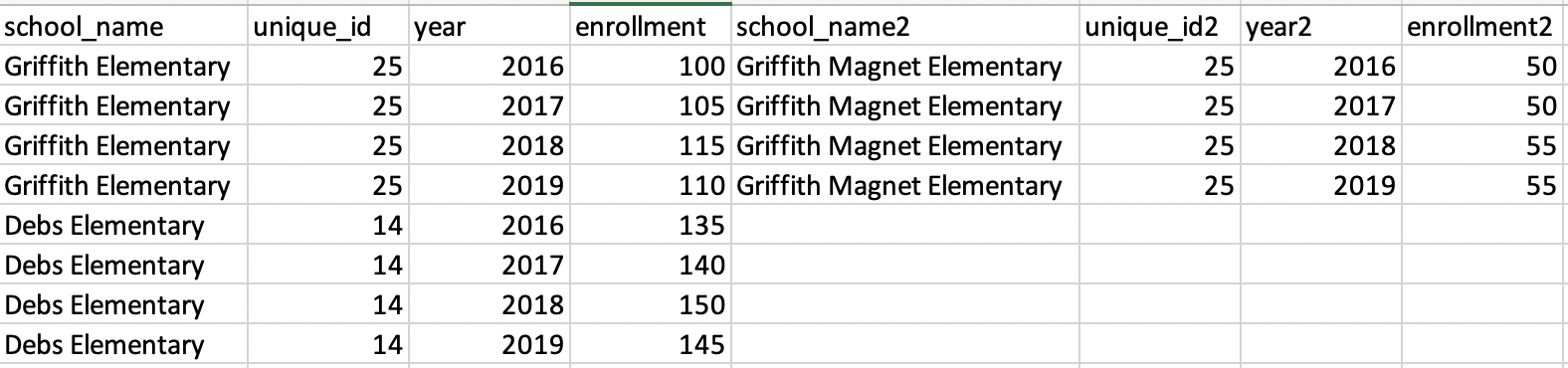
# A tibble: 8 x 8
school1 year1 unique_id1 enrollment1 school2 year2 unique_id2 enrollment2
<chr> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> <dbl>
1 Griffith Elementary 2016 25 100 Griffith Magnet Elementary 2016 25 50
2 Griffith Elementary 2017 25 105 Griffith Magnet Elementary 2017 25 50
3 Griffith Elementary 2018 25 115 Griffith Magnet Elementary 2018 25 55
4 Griffith Elementary 2019 25 110 Griffith Magnet Elementary 2019 25 55
5 Debs Elementary 2016 14 135 <NA> NA NA NA
6 Debs Elementary 2017 14 140 <NA> NA NA NA
7 Debs Elementary 2018 14 150 <NA> NA NA NA
8 Debs Elementary 2019 14 145 <NA> NA NA NA页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/68503591
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号