
Bigquery正则表达式在多个空格后提取数字
请您帮助使用以下示例行中的regexp_extract数字:
- 11BARIIOTA0292DEBORAH (空间) OLLA (空间) JENNY (长-多空间) 0000001242202173171 (space)
- 11SBADIOTA0300MICHELLE (空间) MARGARETE (长-多空间) 0040170225 (space)
- 11NITYIOTA0300SYAHLA (空间) RYAN (长-多个空间)613821914423 (空间)
转入:
- 0000001642202173171
- 0040170225
- 613821914423
fyi:长-多个空间大约是40-50个空间。
谢谢
回答 3
Stack Overflow用户
发布于 2021-07-27 13:31:15
考虑以下方法
select array_reverse(split(trim(col_name), ' '))[offset(0)]
from your_table 如果应用于问题中的样本数据,则输出为
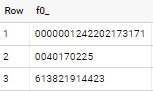
Stack Overflow用户
发布于 2021-07-27 08:52:23
对于以一个或多个空格结束的行,“长-多空间”为40-50个空格。
这里有一些不同的匹配表达,取决于你的需要.
匹配:^.* {40,50}(\d+) +$
替换: Group1
匹配:^[A-Z\d]+(?: [A-Z]+){1,2} {40,50}(\d+) +$
替换: Group1
使用regexp_extract,我认为语法看起来更像..。
regexp_extract(filename,'^.* {40,50}(\d+) +$', 1)
regexp_extract(filename,'^[A-Z\d]+(?: [A-Z]+){1,2} {40,50}(\d+) +$', 1)
{1,2}是与1名或-2名(如Line1上的OLLA和JENNY )匹配的名称。
使用{1,9}匹配这些空格分隔的名称中的1-9个。
(对于“长-多个空格”,{40,50}与此相同)
Stack Overflow用户
发布于 2021-07-27 08:21:28
您可以将字符串转换为简单的空格分隔值,然后在该结果字符串的基础上使用regexp_extract提取数值。
select REGEXP_REPLACE(REGEXP_REPLACE("11BARIIOTA0292DEBORAH OLLA JENNY 0000001242202173171"," ",""),'[^0-9 ]','');https://stackoverflow.com/questions/68540344
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号