
使用python漂亮的汤从网页中生成所有图像urls的列表
我正在学习BeautifulSoup,我想从一个网页(https://www.kaggle.com/navoneel/brain-mri-images-for-brain-tumor-detection)中列出所有的图像urls。
import requests
from bs4 import BeautifulSoup
url = 'https://www.kaggle.com/navoneel/brain-mri-images-for-brain-tumor-detection/'
reqs = requests.get(url)
soup = BeautifulSoup(reqs.text, 'html.parser')
for link in soup.find_all('a'):
print(link.get('href'))上面的代码不会产生任何图像urls。
当我print(soup)时,我也看不到任何图像urls。
但是当我右键单击其中一个图片并手动复制链接时,我会发现url以https://storage.googleapis.com/kagglesdsdata/datasets/165566/377107/开头。
因此,我尝试为上述代码设置url = 'https://storage.googleapis.com/kagglesdsdata/datasets/165566/377107/',但这也不会产生任何图像urls。
谢谢你的帮助!
回答 3
Stack Overflow用户
发布于 2021-08-03 18:55:50
因为它不在页面源代码中,所以它很可能是由Javascript加载的。您可以查看Javascript,看看它是在哪里生成的,或者,如果您只是使用它来学习BeautifulSoup,则可以使用硒获得页面源代码。Selenium使用Chromedriver,因此您需要在回购中有一个chromedriver。(从这里提取win32.zip)。其中92.0.4515.107是您想要的版本,或者是您可以看到的最新版本这里)
from selenium import webdriver
from bs4 import BeautifulSoup
url = 'https://www.kaggle.com/navoneel/brain-mri-images-for-brain-tumor-detection/'
driver = webdriver.Chrome()
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'html.parser')
# parse the soup as you normally would from here如果您转到Chrome工具,您可以看到对这些图像的请求:
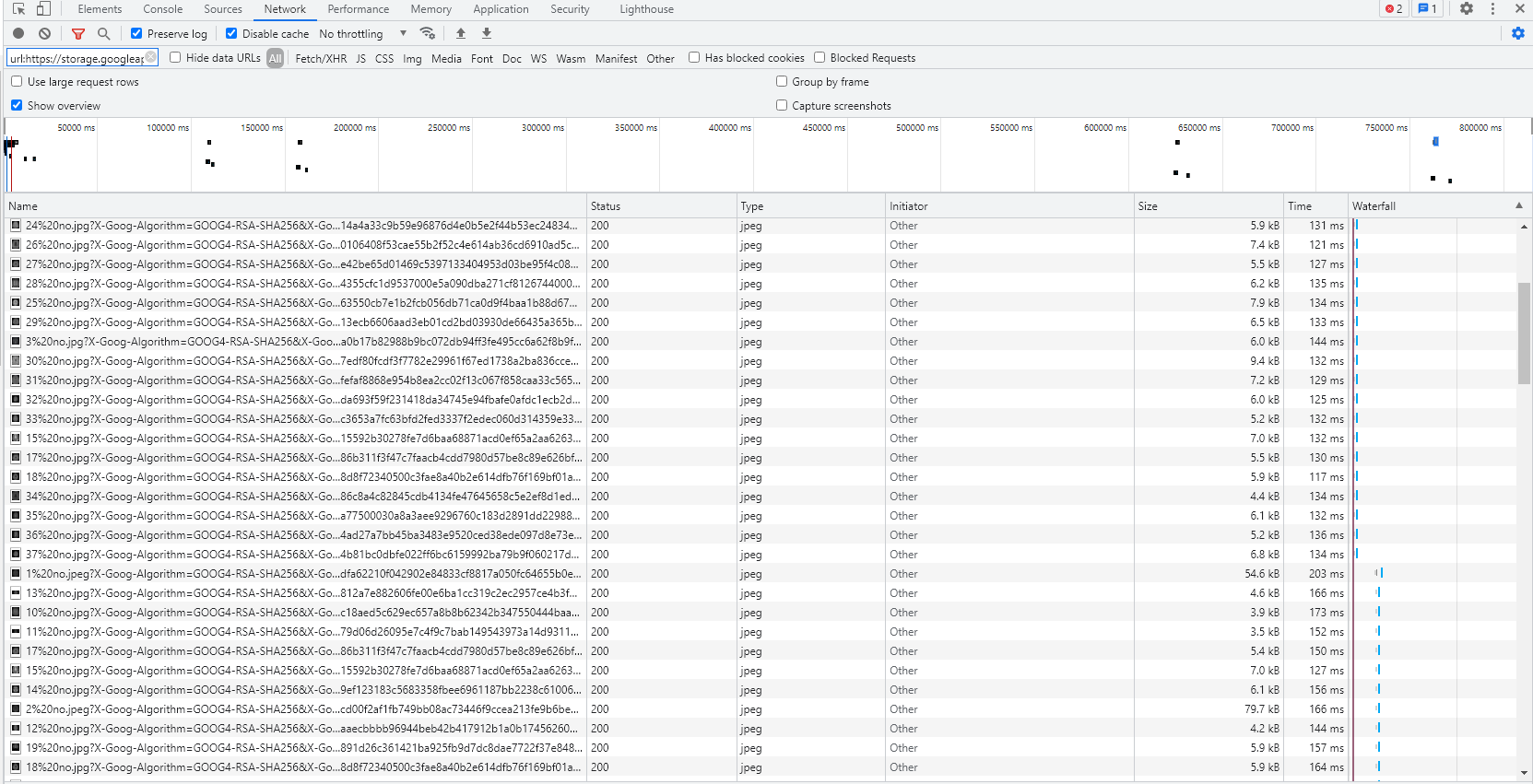
。
如果单击其中一个请求,可以看到这些请求具有一些查询字符串参数,其值类似于X-Goog-Signature和X-Goog-Algorithm。

。
要获得这个完整的URL,您需要将POST请求复制到https://www.kaggle.com/requests/GetDataViewExternalRequest,后者返回如下所示的JSON对象:
{"result":{"dataView":{"type":"url","dataTable":null,"dataUrl":{"url":"https://storage.googleapis.com/kagglesdsdata/datasets/165566/377107/no/1%20no.jpeg?X-Goog-Algorithm=GOOG4-RSA-SHA256\u0026X-Goog-Credential=databundle-worker-v2%40kaggle-161607.iam.gserviceaccount.com%2F20210801%2Fauto%2Fstorage%2Fgoog4_request\u0026X-Goog-Date=20210801T194627Z\u0026X-Goog-Expires=345599\u0026X-Goog-SignedHeaders=host\u0026X-Goog-Signature=2f3672e41a5821b19eb88a8452237a36943ca0cb54874ec47e47c832480870f1ae29ba4cab3e3717ab1decdb74012135bdb1324b85fd8159084dd9587f5504dbf60f6890f12277e418ddbbf61c720083ce7cca6b8936fa45cb9132a396c12136106c6dcfca8574475156f199169b2eecee7fd51fd784d7ddec3f8e3b80b75a17216893ffa22248e98e9bb5cae7cd5b3598e7f3fbbc6e51c24c864c8746c9fe202d1f6a221baea2f300dedf4ba62eb510d9369607ab2f6e659e3b4e4a18e763943632b110c57e223ffb9f1c09db8dac32da6e273f6248c5146dce8d5633ba38787394852b4bcc240dfa62210f042902e84833cf8817a050fc64655b0ed5f43ac9","type":"image"},"dataRaw":null,"dataCase":"dataUrl"}},"wasSuccessful":true}它很容易被简单的代码解析,如:
r = request.post("https://www.kaggle.com/requests/GetDataViewExternalRequest", data=data)
url = r.json()["result"]["dataView"]["dataUrl"]产生这些数据的困难之处在于,如下所示:
data = {
"verificationInfo": {
"competitionId": None,
"datasetId": 165566,
"databundleVersionId": 391742,
"datasetHashLink": None
},
"firestorePath": "hIPSqqCWJs6oriNI20r6/versions/kKBcaXwa0lr8cvBuOMna/directories/no/files/1 no.jpeg",
"tableQuery": None
}我希望这些值中的大多数都是静态的,这可能是firestorePath的变化。通过非常快速的搜索,看起来所有这些值都可以使用regex或BeautifulSoup从页面中抓取。
请求还有一些头部,包括__requestverificationtoken和x-xsrf-token。看起来他们是来验证你的请求的,他们可能是可撤销的,也可能不是。但是,它们的价值是相等的。您还需要将这些头添加到请求中。我推荐本站来帮助轻松创建请求。您只需检查请求并删除任何非常量的值。
总之,这并不容易!如果速度不是问题,请使用selenium,如果有问题,请使用请求并解决所有这些问题。
毕竟,最好的选择就是使用他们的API接口,就像普瑞斯所说的那样。这将是非常容易使用。
Stack Overflow用户
发布于 2021-08-03 18:27:58
刮刀看起来不错,所以问题通常是服务器试图保护自己免受…刮板!BeautifulSoup是一个很好的工具,可以抓取静态页面,因此问题是当您需要请求页面时:
将用户代理传递给您的请求。
user_agent = # for example 'Mozilla/5.0 (X11; Linux x86_64; rv:89.0) Gecko/20100101 Firefox/88.0'}
response = requests.get(url, headers={ "user-agent": user_agent})如果这不起作用,调查响应(cookie,编码,.)
response = requests.get(url)
for key, value in response.headers.items():
print(key, ":", value)如果你只想要链接,也许这样会更好
for link in soup.find_all('a', href=True): # so you are sure the you don't get an error when retrieving the value
print(link['href'])Stack Overflow用户
发布于 2021-08-03 18:38:22
就我个人而言,我会考虑使用Kaggle的官方API来访问数据。它们似乎并没有特别严格的限制,一旦你弄清楚了,也应该可以上传解决方案:https://www.kaggle.com/docs/api
只是为了把你推向正确的方向:
“Kaggle API和CLI工具提供了与Kaggle上的数据集交互的简单方法。可用的命令可以使搜索和下载Kaggle数据集成为您的数据科学工作流的无缝部分。
如果您尚未安装使用命令行工具或生成API令牌所需的Kaggle包,请先查看入门步骤。
通过CLI与数据集交互的一些命令包括:
kaggle datasets list -s [KEYWORD]: list datasets matching a search term
kaggle datasets download -d [DATASET]: download files associated with a datasethttps://stackoverflow.com/questions/68640856
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号