
创建一个接受R中另一列的初始值的新列
创建一个接受R中另一列的初始值的新列
提问于 2021-08-05 09:28:13
我正在处理一个横截面数据集。我想要创建一个名为" initial“的新列,它将包含另一列的初始值。更具体地说,对于每个国家,第一栏首字母取有数据的第一年另一栏“比率”的值,其余年份的数值为0。样本代码:
country <- c(rep(c("A","B","C","D"),each=5))
year <- c(1980:1984, 1980: 1984, 1980:1984, 1980:1984)
ratio <- runif(n = 20, min = 0.20, max = 0.40)
mydata <- data.frame(country, year, ratio)
mydata$ratio[[1]] <- NA
mydata$ratio[6:7] <- NA
mydata$ratio[16:18] <- NA我想获得的输出如下所示:
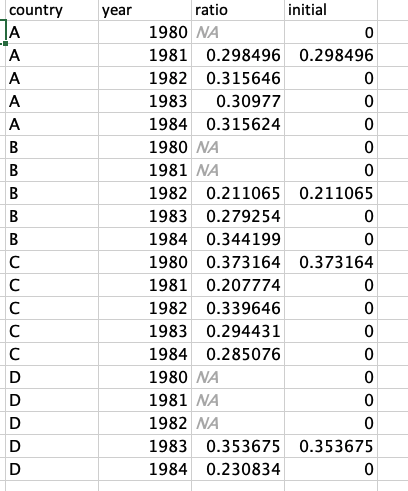
在R中是否有这样的方法,最好使用dplyr包?
非常感谢提前!
回答 4
Stack Overflow用户
回答已采纳
发布于 2021-08-05 09:58:15
通过使用dplyr::first,您可以:
library(dplyr)
mydata %>%
group_by(country) %>%
mutate(initial = first(ratio[!is.na(ratio)]),
initial = ifelse(is.na(ratio) | ratio != initial, 0, initial)) %>%
ungroup()
#> # A tibble: 20 × 4
#> country year ratio initial
#> <chr> <int> <dbl> <dbl>
#> 1 A 1980 NA 0
#> 2 A 1981 0.387 0.387
#> 3 A 1982 0.257 0
#> 4 A 1983 0.366 0
#> 5 A 1984 0.328 0
#> 6 B 1980 NA 0
#> 7 B 1981 NA 0
#> 8 B 1982 0.227 0.227
#> 9 B 1983 0.331 0
#> 10 B 1984 0.341 0
#> 11 C 1980 0.292 0.292
#> 12 C 1981 0.344 0
#> 13 C 1982 0.387 0
#> 14 C 1983 0.251 0
#> 15 C 1984 0.292 0
#> 16 D 1980 NA 0
#> 17 D 1981 NA 0
#> 18 D 1982 NA 0
#> 19 D 1983 0.295 0.295
#> 20 D 1984 0.312 0数据
set.seed(42)
country <- c(rep(c("A","B","C","D"),each=5))
year <- c(1980:1984, 1980: 1984, 1980:1984, 1980:1984)
ratio <- runif(n = 20, min = 0.20, max = 0.40)
mydata <- data.frame(country, year, ratio)
mydata$ratio[[1]] <- NA
mydata$ratio[6:7] <- NA
mydata$ratio[16:18] <- NAStack Overflow用户
发布于 2021-08-05 10:14:46
library(tidyverse)
mydata2 <- mydata %>%
group_by(country) %>%
filter(!is.na(ratio)) %>%
mutate(year_rank = rank(year)) %>%
mutate(initial = if_else(year_rank == 1, ratio, 0)) %>%
right_join(., mydata, by = c('country', 'year', 'ratio')) %>%
replace_na(list(initial = '0')) %>%
arrange(country, year) %>%
select(-year_rank)Stack Overflow用户
发布于 2021-08-05 09:58:06
这可能会有所改进,但我得到了您的预期输出:
library(dplyr)
mydata %>%
group_by(country) %>%
filter(!is.na(ratio)) %>%
filter(year == min(year)) %>%
rename(initial = ratio) %>%
full_join(., mydata) %>%
mutate(initial = ifelse(is.na(initial), 0, initial)) %>%
arrange(country, year) %>%
relocate(initial, .after = last_col())输出:
country year ratio initial
<chr> <int> <dbl> <dbl>
1 A 1980 NA 0
2 A 1981 0.341 0.341
3 A 1982 0.330 0
4 A 1983 0.219 0
5 A 1984 0.269 0
6 B 1980 NA 0
7 B 1981 NA 0
8 B 1982 0.365 0.365
9 B 1983 0.210 0
10 B 1984 0.334 0
11 C 1980 0.284 0.284
12 C 1981 0.251 0
13 C 1982 0.358 0
14 C 1983 0.288 0
15 C 1984 0.261 0
16 D 1980 NA 0
17 D 1981 NA 0
18 D 1982 NA 0
19 D 1983 0.252 0.252
20 D 1984 0.301 0 页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/68663993
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号