
COUNTA()和AVERAGEX()在DAX / Power BI中的结合
COUNTA()和AVERAGEX()在DAX / Power BI中的结合
提问于 2021-08-06 11:03:06
我有一个简单的数据集与一些运动员的训练课程。比方说,我想想象有多少次的训练是作为,一个运动员的平均数量,无论是在总体上还是被现有的俱乐部分割。我希望数据集有点自我描述。
为了用运动员的数量来规范活动的数量,我使用了两种标准:
TotalSessions = COUNTA(Tab_Sessions[Session key])
AvgAthlete = AVERAGEX(VALUES(Tab_Sessions[Athlete]),[TotalSessions])在下面所示的两个可视化中,我给出了AvgAthlete作为所需的值。如果我在俱乐部上做了一个过滤器,值就像预期的那样,但是没有过滤,我得到了一些奇怪的值。
我猜发生的是,由于运动员B不做任何力量,所以运动员B不包括在力量的赋范因子中。有一个DAX函数可以解决这个问题吗?,如果我没有以层次结构(类型强度)的形式进行培训,那么使用计算的列进行某种解决方法是非常简单的,但是它不能处理层次类别。在excel中计算的预期结果如下:

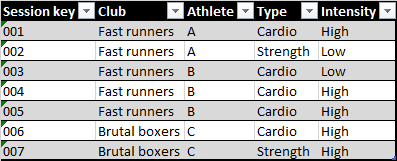
数据集为csv:
Session key;Club;Athlete;Type;Intensity
001;Fast runners;A;Cardio;High
002;Fast runners;A;Strength;Low
003;Fast runners;B;Cardio;Low
004;Fast runners;B;Cardio;High
005;Fast runners;B;Cardio;High
006;Brutal boxers;C;Cardio;High
007;Brutal boxers;C;Strength;High回答 1
Stack Overflow用户
发布于 2021-08-09 07:50:08
如果您特别希望通过在Club选择中所做的任何选择来聚合这个值,那么只需编写一个简单的度量:
AvgAthlete =
VAR _athletes =
CALCULATE (
DISTINCTCOUNT ( 'Table'[Athlete] ) ,
ALLEXCEPT ( 'Table' , 'Table'[Club] )
)
RETURN
DIVIDE (
[Sessions] ,
_athletes
)在这里,我们在Athlete列中使用了一个不同的值计数,除Club列上的所有过滤器之外,所有过滤器都被移除。就我所理解的问题而言,这就是你所追求的分母。
除以这个数量的运动员的课程总数。结果如下:
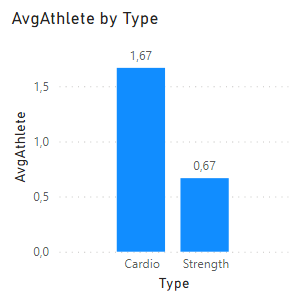
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/68680536
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号