
使用Databricks作业输出Hadoop HFile
我将使用Databricks作业来使用saveAsNewAPIHadoopFile接口来编写HFile。
在本地火花测试实例中,它工作得很好,但是在Databricks作业中,它失败了:NoClassDefFoundError: Could not initialize class org.apache.hadoop.hbase.io.hfile.HFile。
详谈
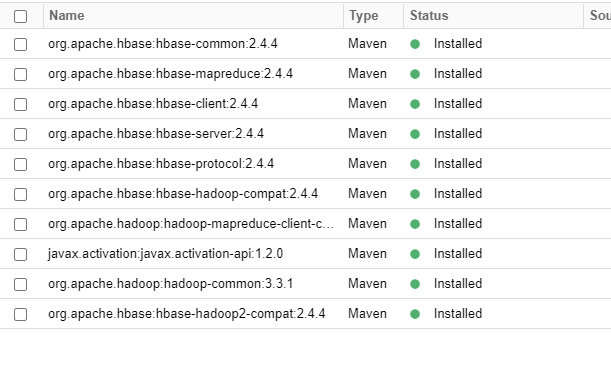
我当前的依赖关系如下所示:
我的测试笔记本有以下步骤:
1.一些进口
import java.sql.Timestamp
import java.nio.ByteBuffer
import org.apache.hadoop.hbase.client.{Admin, ConnectionFactory, HTable}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.{HBaseConfiguration, KeyValue, TableName}
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2
import java.util.UUID
import org.apache.hadoop.mapreduce.Job2.安装hbase配置(从HBase集群复制)
val hbaseConfig = HBaseConfiguration.create()
hbaseConfig.set("dfs.domain.socket.path", "/var/lib/hadoop-hdfs/dn_socket")
hbaseConfig.set("dfs.support.append", "false")
[...]
hbaseConfig.set("zookeeper.session.timeout", "120000")
hbaseConfig.set("zookeeper.znode.parent", "/hbase-unsecure")
hbaseConfig.set("hbase.mapreduce.hfileoutputformat.table.name", "DeviceData")3.保存DataSet
mappedData.saveAsNewAPIHadoopFile(
stagingDir,
classOf[ImmutableBytesWritable],
classOf[KeyValue],
classOf[HFileOutputFormat2],
hbaseConfig
)误差
Caused by: Job aborted due to stage failure.
Caused by: Task failed while writing rows
Caused by: NoClassDefFoundError: Could not initialize class org.apache.hadoop.hbase.io.hfile.HFile
at org.apache.spark.internal.io.SparkHadoopWriter$.write(SparkHadoopWriter.scala:109)
at org.apache.spark.rdd.PairRDDFunctions.$anonfun$saveAsNewAPIHadoopDataset$1(PairRDDFunctions.scala:1077)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:165)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:125)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:419)
at org.apache.spark.rdd.PairRDDFunctions.saveAsNewAPIHadoopDataset(PairRDDFunctions.scala:1075)
at org.apache.spark.rdd.PairRDDFunctions.$anonfun$saveAsNewAPIHadoopFile$2(PairRDDFunctions.scala:994)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:165)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:125)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:419)
at org.apache.spark.rdd.PairRDDFunctions.saveAsNewAPIHadoopFile(PairRDDFunctions.scala:985)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$$iw$$iw$$iw$$iw$$iw$$iw$$iw$$iw$$iw.<init>(command-4454301442308183:6)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$$iw$$iw$$iw$$iw$$iw$$iw$$iw$$iw.<init>(command-4454301442308183:90)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$$iw$$iw$$iw$$iw$$iw$$iw$$iw.<init>(command-4454301442308183:92)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$$iw$$iw$$iw$$iw$$iw$$iw.<init>(command-4454301442308183:94)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$$iw$$iw$$iw$$iw$$iw.<init>(command-4454301442308183:96)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$$iw$$iw$$iw$$iw.<init>(command-4454301442308183:98)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$$iw$$iw$$iw.<init>(command-4454301442308183:100)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$$iw$$iw.<init>(command-4454301442308183:102)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$$iw.<init>(command-4454301442308183:104)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read.<init>(command-4454301442308183:106)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$.<init>(command-4454301442308183:110)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$.<clinit>(command-4454301442308183)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$eval$.$print$lzycompute(<notebook>:7)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$eval$.$print(<notebook>:6)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$eval.$print(<notebook>)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at scala.tools.nsc.interpreter.IMain$ReadEvalPrint.call(IMain.scala:745)
at scala.tools.nsc.interpreter.IMain$Request.loadAndRun(IMain.scala:1021)
at scala.tools.nsc.interpreter.IMain.$anonfun$interpret$1(IMain.scala:574)
at scala.reflect.internal.util.ScalaClassLoader.asContext(ScalaClassLoader.scala:41)
at scala.reflect.internal.util.ScalaClassLoader.asContext$(ScalaClassLoader.scala:37)
at scala.reflect.internal.util.AbstractFileClassLoader.asContext(AbstractFileClassLoader.scala:41)
at scala.tools.nsc.interpreter.IMain.loadAndRunReq$1(IMain.scala:573)
at scala.tools.nsc.interpreter.IMain.interpret(IMain.scala:600)
at scala.tools.nsc.interpreter.IMain.interpret(IMain.scala:570)
at com.databricks.backend.daemon.driver.DriverILoop.execute(DriverILoop.scala:219)
at com.databricks.backend.daemon.driver.ScalaDriverLocal.$anonfun$repl$1(ScalaDriverLocal.scala:235)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at com.databricks.backend.daemon.driver.DriverLocal$TrapExitInternal$.trapExit(DriverLocal.scala:903)
at com.databricks.backend.daemon.driver.DriverLocal$TrapExit$.apply(DriverLocal.scala:856)
at com.databricks.backend.daemon.driver.ScalaDriverLocal.repl(ScalaDriverLocal.scala:235)
at com.databricks.backend.daemon.driver.DriverLocal.$anonfun$execute$13(DriverLocal.scala:544)
at com.databricks.logging.UsageLogging.$anonfun$withAttributionContext$1(UsageLogging.scala:240)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62)
at com.databricks.logging.UsageLogging.withAttributionContext(UsageLogging.scala:235)
at com.databricks.logging.UsageLogging.withAttributionContext$(UsageLogging.scala:232)
at com.databricks.backend.daemon.driver.DriverLocal.withAttributionContext(DriverLocal.scala:53)
at com.databricks.logging.UsageLogging.withAttributionTags(UsageLogging.scala:279)
at com.databricks.logging.UsageLogging.withAttributionTags$(UsageLogging.scala:271)
at com.databricks.backend.daemon.driver.DriverLocal.withAttributionTags(DriverLocal.scala:53)
at com.databricks.backend.daemon.driver.DriverLocal.execute(DriverLocal.scala:521)
at com.databricks.backend.daemon.driver.DriverWrapper.$anonfun$tryExecutingCommand$1(DriverWrapper.scala:689)
at scala.util.Try$.apply(Try.scala:213)
at com.databricks.backend.daemon.driver.DriverWrapper.tryExecutingCommand(DriverWrapper.scala:681)
at com.databricks.backend.daemon.driver.DriverWrapper.getCommandOutputAndError(DriverWrapper.scala:522)
at com.databricks.backend.daemon.driver.DriverWrapper.executeCommand(DriverWrapper.scala:634)
at com.databricks.backend.daemon.driver.DriverWrapper.runInnerLoop(DriverWrapper.scala:427)
at com.databricks.backend.daemon.driver.DriverWrapper.runInner(DriverWrapper.scala:370)
at com.databricks.backend.daemon.driver.DriverWrapper.run(DriverWrapper.scala:221)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 3.0 failed 4 times, most recent failure: Lost task 1.3 in stage 3.0 (TID 38) (10.42.240.4 executor driver): org.apache.spark.SparkException: Task failed while writing rows
at org.apache.spark.internal.io.SparkHadoopWriter$.executeTask(SparkHadoopWriter.scala:166)
at org.apache.spark.internal.io.SparkHadoopWriter$.$anonfun$write$1(SparkHadoopWriter.scala:92)
at org.apache.spark.scheduler.ResultTask.$anonfun$runTask$3(ResultTask.scala:75)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.scheduler.ResultTask.$anonfun$runTask$1(ResultTask.scala:75)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:55)
at org.apache.spark.scheduler.Task.doRunTask(Task.scala:150)
at org.apache.spark.scheduler.Task.$anonfun$run$1(Task.scala:119)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.scheduler.Task.run(Task.scala:91)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$13(Executor.scala:788)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1643)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$4(Executor.scala:791)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:647)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.NoClassDefFoundError: Could not initialize class org.apache.hadoop.hbase.io.hfile.HFile
at org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2$1.getNewWriter(HFileOutputFormat2.java:419)
at org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2$1.write(HFileOutputFormat2.java:321)
at org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2$1.write(HFileOutputFormat2.java:239)
at org.apache.spark.internal.io.HadoopMapReduceWriteConfigUtil.write(SparkHadoopWriter.scala:371)
at org.apache.spark.internal.io.SparkHadoopWriter$.$anonfun$executeTask$1(SparkHadoopWriter.scala:141)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1677)
at org.apache.spark.internal.io.SparkHadoopWriter$.executeTask(SparkHadoopWriter.scala:138)
... 19 more
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2765)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2712)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2706)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2706)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1255)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1255)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1255)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2973)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2914)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2902)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:1028)
at org.apache.spark.SparkContext.runJobInternal(SparkContext.scala:2446)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2429)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2467)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2499)
at org.apache.spark.internal.io.SparkHadoopWriter$.write(SparkHadoopWriter.scala:87)
at org.apache.spark.rdd.PairRDDFunctions.$anonfun$saveAsNewAPIHadoopDataset$1(PairRDDFunctions.scala:1077)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:165)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:125)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:419)
at org.apache.spark.rdd.PairRDDFunctions.saveAsNewAPIHadoopDataset(PairRDDFunctions.scala:1075)
at org.apache.spark.rdd.PairRDDFunctions.$anonfun$saveAsNewAPIHadoopFile$2(PairRDDFunctions.scala:994)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:165)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:125)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:419)
at org.apache.spark.rdd.PairRDDFunctions.saveAsNewAPIHadoopFile(PairRDDFunctions.scala:985)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$$iw$$iw$$iw$$iw$$iw$$iw$$iw$$iw$$iw.<init>(command-4454301442308183:6)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$$iw$$iw$$iw$$iw$$iw$$iw$$iw$$iw.<init>(command-4454301442308183:90)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$$iw$$iw$$iw$$iw$$iw$$iw$$iw.<init>(command-4454301442308183:92)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$$iw$$iw$$iw$$iw$$iw$$iw.<init>(command-4454301442308183:94)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$$iw$$iw$$iw$$iw$$iw.<init>(command-4454301442308183:96)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$$iw$$iw$$iw$$iw.<init>(command-4454301442308183:98)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$$iw$$iw$$iw.<init>(command-4454301442308183:100)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$$iw$$iw.<init>(command-4454301442308183:102)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$$iw.<init>(command-4454301442308183:104)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read.<init>(command-4454301442308183:106)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$.<init>(command-4454301442308183:110)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$read$.<clinit>(command-4454301442308183)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$eval$.$print$lzycompute(<notebook>:7)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$eval$.$print(<notebook>:6)
at $line3506744ecc8e4b3a8d207e04b18fbe0595.$eval.$print(<notebook>)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at scala.tools.nsc.interpreter.IMain$ReadEvalPrint.call(IMain.scala:745)
at scala.tools.nsc.interpreter.IMain$Request.loadAndRun(IMain.scala:1021)
at scala.tools.nsc.interpreter.IMain.$anonfun$interpret$1(IMain.scala:574)
at scala.reflect.internal.util.ScalaClassLoader.asContext(ScalaClassLoader.scala:41)
at scala.reflect.internal.util.ScalaClassLoader.asContext$(ScalaClassLoader.scala:37)
at scala.reflect.internal.util.AbstractFileClassLoader.asContext(AbstractFileClassLoader.scala:41)
at scala.tools.nsc.interpreter.IMain.loadAndRunReq$1(IMain.scala:573)
at scala.tools.nsc.interpreter.IMain.interpret(IMain.scala:600)
at scala.tools.nsc.interpreter.IMain.interpret(IMain.scala:570)
at com.databricks.backend.daemon.driver.DriverILoop.execute(DriverILoop.scala:219)
at com.databricks.backend.daemon.driver.ScalaDriverLocal.$anonfun$repl$1(ScalaDriverLocal.scala:235)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at com.databricks.backend.daemon.driver.DriverLocal$TrapExitInternal$.trapExit(DriverLocal.scala:903)
at com.databricks.backend.daemon.driver.DriverLocal$TrapExit$.apply(DriverLocal.scala:856)
at com.databricks.backend.daemon.driver.ScalaDriverLocal.repl(ScalaDriverLocal.scala:235)
at com.databricks.backend.daemon.driver.DriverLocal.$anonfun$execute$13(DriverLocal.scala:544)
at com.databricks.logging.UsageLogging.$anonfun$withAttributionContext$1(UsageLogging.scala:240)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62)
at com.databricks.logging.UsageLogging.withAttributionContext(UsageLogging.scala:235)
at com.databricks.logging.UsageLogging.withAttributionContext$(UsageLogging.scala:232)
at com.databricks.backend.daemon.driver.DriverLocal.withAttributionContext(DriverLocal.scala:53)
at com.databricks.logging.UsageLogging.withAttributionTags(UsageLogging.scala:279)
at com.databricks.logging.UsageLogging.withAttributionTags$(UsageLogging.scala:271)
at com.databricks.backend.daemon.driver.DriverLocal.withAttributionTags(DriverLocal.scala:53)
at com.databricks.backend.daemon.driver.DriverLocal.execute(DriverLocal.scala:521)
at com.databricks.backend.daemon.driver.DriverWrapper.$anonfun$tryExecutingCommand$1(DriverWrapper.scala:689)
at scala.util.Try$.apply(Try.scala:213)
at com.databricks.backend.daemon.driver.DriverWrapper.tryExecutingCommand(DriverWrapper.scala:681)
at com.databricks.backend.daemon.driver.DriverWrapper.getCommandOutputAndError(DriverWrapper.scala:522)
at com.databricks.backend.daemon.driver.DriverWrapper.executeCommand(DriverWrapper.scala:634)
at com.databricks.backend.daemon.driver.DriverWrapper.runInnerLoop(DriverWrapper.scala:427)
at com.databricks.backend.daemon.driver.DriverWrapper.runInner(DriverWrapper.scala:370)
at com.databricks.backend.daemon.driver.DriverWrapper.run(DriverWrapper.scala:221)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.spark.SparkException: Task failed while writing rows
at org.apache.spark.internal.io.SparkHadoopWriter$.executeTask(SparkHadoopWriter.scala:166)
at org.apache.spark.internal.io.SparkHadoopWriter$.$anonfun$write$1(SparkHadoopWriter.scala:92)
at org.apache.spark.scheduler.ResultTask.$anonfun$runTask$3(ResultTask.scala:75)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.scheduler.ResultTask.$anonfun$runTask$1(ResultTask.scala:75)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:55)
at org.apache.spark.scheduler.Task.doRunTask(Task.scala:150)
at org.apache.spark.scheduler.Task.$anonfun$run$1(Task.scala:119)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.scheduler.Task.run(Task.scala:91)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$13(Executor.scala:788)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1643)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$4(Executor.scala:791)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:647)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.NoClassDefFoundError: Could not initialize class org.apache.hadoop.hbase.io.hfile.HFile
at org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2$1.getNewWriter(HFileOutputFormat2.java:419)
at org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2$1.write(HFileOutputFormat2.java:321)
at org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2$1.write(HFileOutputFormat2.java:239)
at org.apache.spark.internal.io.HadoopMapReduceWriteConfigUtil.write(SparkHadoopWriter.scala:371)
at org.apache.spark.internal.io.SparkHadoopWriter$.$anonfun$executeTask$1(SparkHadoopWriter.scala:141)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1677)
at org.apache.spark.internal.io.SparkHadoopWriter$.executeTask(SparkHadoopWriter.scala:138)
at org.apache.spark.internal.io.SparkHadoopWriter$.$anonfun$write$1(SparkHadoopWriter.scala:92)
at org.apache.spark.scheduler.ResultTask.$anonfun$runTask$3(ResultTask.scala:75)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.scheduler.ResultTask.$anonfun$runTask$1(ResultTask.scala:75)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:55)
at org.apache.spark.scheduler.Task.doRunTask(Task.scala:150)
at org.apache.spark.scheduler.Task.$anonfun$run$1(Task.scala:119)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.scheduler.Task.run(Task.scala:91)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$13(Executor.scala:788)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1643)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$4(Executor.scala:791)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at com.databricks.spark.util.ExecutorFrameProfiler$.record(ExecutorFrameProfiler.scala:110)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:647)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)问题是
我想尽一切办法来理解Databricks工作和我的本地工作之间的区别。我完全没有想法了。
更新1- 2021-08-09
为了使用默认安装的并避免冲突,我们也没有将已安装的lib减少到最低限度。
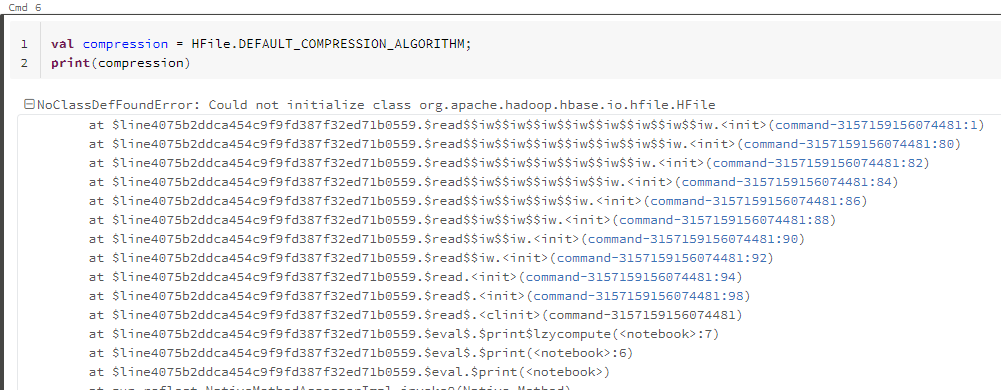
即使是在非常基本的静态操作中,仍然会得到这个微小的错误。
更新2
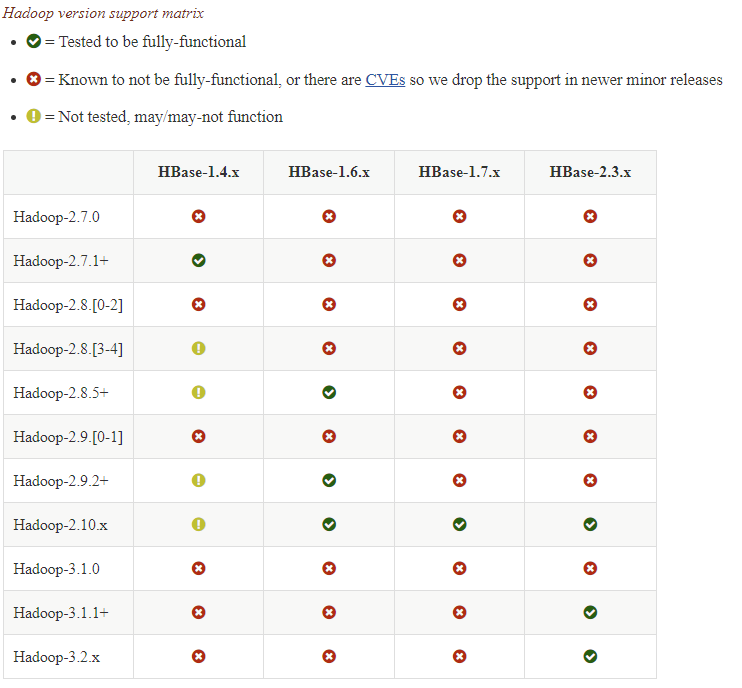
基于HBase的兼容性矩阵,最好知道DataBricks集群默认使用的Hadoop版本,以及如何用兼容的版本替换它们。
回答 1
Stack Overflow用户
发布于 2021-08-19 08:38:27
基本的问题是缺少一些依赖关系。我无法检测到这一点的一点是,在集群重新启动之后,具体错误只显示了一次。在此之后,正在运行的集群上的任何操作都只显示误导性错误NoClassDefFoundError。我认为这是因为在集群开始时,HBase库正在做一些初步的工作。如果失败,在重新启动群集之前,它将不会产生任何有用的错误消息。
这里的具体错误是缺少两个库org.apache.hbase:hbase-metrics和org.apache.hbase:hbase-metrics-api。
https://stackoverflow.com/questions/68674691
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号