
全局索引(术语分区)是否包含整个行本身?
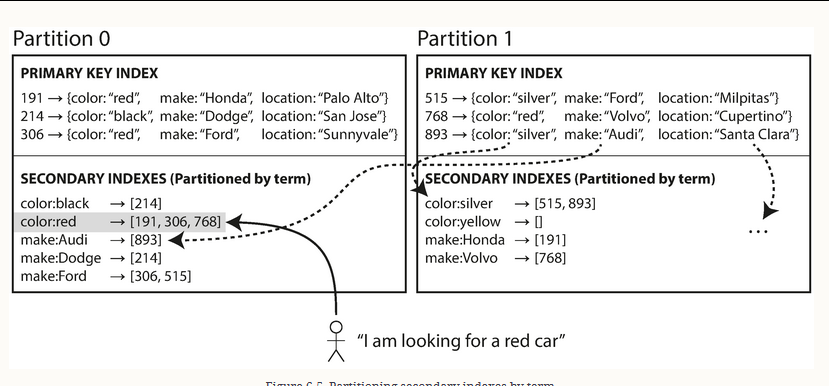
我正在阅读Designing Data Intensive Applications一书,这本书目前是关于分区的一章,其中描述了一个例子,即本地索引(基于文档的分区)和全局索引,后者是术语分区的。下图显示了全局索引的示例。
书中说,全局索引表现得更好,因为索引可以根据“术语”从单个分区读取。但是,我不明白的是,索引本身是否保存了包含这个术语的所有行,或者后面的索引读取,接下来的查询必须从所有可以包含数据的分区中获取数据?与必须将查询发送到所有分区的本地索引相比,这几乎没有什么效率,这取决于分区的数量。
在这一章的总结中,作者写道
术语分区索引(全局索引),其中使用索引值将辅助索引分开分区。辅助索引中的条目可以包括来自主键的所有分区的记录。在编写文档时,需要更新辅助索引的几个分区;但是,可以从单个分区读取数据。
我是不是漏掉了什么?
回答 1
Stack Overflow用户
发布于 2022-03-12 12:38:01
在索引读取后,必须执行下一次查询,以便从可以包含数据的所有分区中获取数据
是的,我认为是这样的,因为将数据与索引(聚集索引)一起存储可能会导致更痛苦的一致性问题。在最坏的情况下,我同意您需要执行类似于文档分区的分散收集查询。但是,如果用例涉及查询可能位于所有分区的一小部分中的少量数据,那么术语分区(全局)索引可能要好得多。
参考文献:
https://stackoverflow.com/questions/68763647
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号