
提取div标记中的多个信息但类名相同
提取div标记中的多个信息但类名相同
提问于 2021-08-14 12:39:36
我有一个https://www.serviceseeking.com.au/profile/106871-cld-electrical?source=网站
由此,我只对与国际中心能源安全相关的名称、地址、ABN和牌照号码感兴趣。
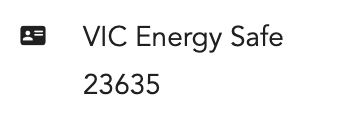
上述所有信息都存在于<div class="row">标记中。但我很难分别提取上述所有信息。
到目前为止,我一直在尝试这样做:
from bs4 import BeautifulSoup # required to parse html
import requests # required to make request
import re
html_text = requests.get('https://www.serviceseeking.com.au/profile/35359-baker-s-electrical-services-p-l?source=').text
soup = BeautifulSoup(html_text,'lxml')
#Electrician Name
name=[]
name = soup.find('div', class_ = "row mt20").text
print(f'Name: {name}')
#Licence Number
res=[]
ln=soup.find_all('div', class_='row')
try:
for item in ln:
if ('VIC Energy Safe' in item.text):
licence = item.select_one('div').text
res = re.findall(r'Safe(\w+)', licence)[0]
res = int(re.search(r'\d+', res).group(0))
#print(res)
except:
print(" ")
print("License Number=",res)输出:
Name: David Baker
License Number= 29402我一直使用相同的技术(如牌照号码)提取地址和荷兰银行。
这个代码似乎对这个网站很好。然而,我有从这个网站的300+配置文件,它似乎不适用于所有的网站。例如,对于此配置文件,它失败了。https://www.serviceseeking.com.au/profile/197521-elcom-electrical-group?source=
有人能给我一个可行的解决方案,轻松地提取所有这些信息吗?
(PS:我想我应该拆分正则字符串,但我不知道该如何拆分)
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-08-14 13:09:32
尝试:
import bs4
import requests
urls = [
"https://www.serviceseeking.com.au/profile/106871-cld-electrical?source=",
"https://www.serviceseeking.com.au/profile/197521-elcom-electrical-group?source=",
]
for url in urls:
soup = BeautifulSoup(requests.get(url).content, "html.parser")
name = soup.select_one(".ficon-user").find_next("div").get_text(strip=True)
addr = (
soup.select_one(".ficon-coverage").find_next("div").get_text(strip=True)
)
abn = soup.select_one('strong:-soup-contains("ABN")').find_next_sibling(
text=True
)
vic = soup.select_one(
'.license-name:-soup-contains("VIC Energy Safe") + div'
)
vic = vic.get_text(strip=True) if vic else "N/A"
print(name)
print(addr)
print(abn)
print(vic) # or print(vic.split("-")[-1]) if you want only the number
print("-" * 80)指纹:
Chris Donovan
Lilydale, VIC
94385612994
23635
--------------------------------------------------------------------------------
Emre Cekuc
Roxburgh Park, VIC
82689908730
REC-28370
--------------------------------------------------------------------------------页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/68783380
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号