
用于NLTK资源的Pyodide文件系统:缺少文件
我正试图在浏览器中使用NLTK,这要感谢吡啶类。Pyodide启动良好,管理加载NLTK,打印它的版本。
然而,尽管包下载看起来很好,但是当调用nltk.sent_tokenize(str)时,NLTK会引发一个错误,即它找不到包"punkt“。
我会说下载的资源在某个地方丢失了,但我不太明白Pyodide / WebAssembly如何管理文件。有什么见解吗?
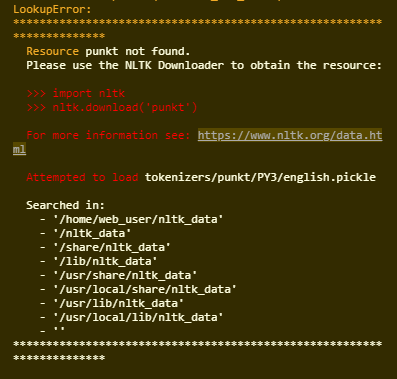
简单版本:
import nltk
nltk.download(pkg)
for sent in nltk.sent_tokenize("Test string"):
print(sent)提供更多详细信息的版本,指定下载目录和服务器url。
import nltk
pkg = "punkt"
downloader = nltk.downloader.Downloader(server_index_url="https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/index.xml")
downloader.download(pkg, download_dir='/nltk_data')
downloader.status(pkg)
for sent in nltk.sent_tokenize("Test string"):
print(sent)完整示例代码:
<!DOCTYPE html>
<html>
<body>
<script type="text/javascript" src="https://cdn.jsdelivr.net/pyodide/v0.18.0/full/pyodide.js"></script>
<script type="text/javascript">
// init Pyodide
async function pyodide_loader() {
let pyodide_premise = loadPyodide({
indexURL: "https://cdn.jsdelivr.net/pyodide/v0.18.0/full/",
});
let pyodide = await pyodide_premise;
await pyodide.loadPackage("micropip");
await pyodide.loadPackage("nltk");
return pyodide_premise;
}
let pyodideReadyPromise = pyodide_loader();
// run Python code and load NLTK
async function load_packages() {
let pyodide = await pyodideReadyPromise;
let output = pyodide.runPython(`
print(f"*** import nltk")
import nltk
print(f"*** NLTK version {nltk.__version__=} imported, downloading resources now")
pkg = "punkt"
nltk.download(pkg)
str = "Just for testing"
for sent in nltk.sent_tokenize(str):
print(sent)
`);
}
load_packages()
</script>
</body>
</html>回答 2
Stack Overflow用户
发布于 2021-09-02 14:53:27
简而言之,用Python下载文件目前无法在Pyodide中工作,因为http.client、requests等需要在浏览器VM中不支持的POSIX套接字。
奇怪的是,nltk.download没有出错
解决办法是手动下载所需的资源,例如,使用JavaScript 取API (如这句话中所示);
from js import fetch
response = await fetch("<url>")
js_buffer = await response.arrayBuffer()
py_buffer = js_buffer.to_py() # this is a memoryview
stream = py_buffer.tobytes() # now we have a bytes object
# that we can finally write under the appropriate path
with open("<file_path>", "wb") as fh:
fh.write(stream)我不太明白Pyodide / WebAssembly如何管理文件。
默认情况下,在每次加载页面时都会重置虚拟文件系统(MEMFS)。您可以使用标准python工具(open、'os‘等)访问它。如果有必要,您也可以使用挂载持久文件系统。
Stack Overflow用户
发布于 2021-11-14 22:03:09
下面是一个用punkt v0.18.1加载pyodide的工作示例。我试图将此作为评论发布到@rth的可接受答案,但字符数超过了240个字符的限制。
from js import fetch
import nltk
from pathlib import Path
import os, sys, io, zipfile
response = await fetch('https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/packages/tokenizers/punkt.zip')
js_buffer = await response.arrayBuffer()
py_buffer = js_buffer.to_py() # this is a memoryview
stream = py_buffer.tobytes() # now we have a bytes object
d = Path("/nltk_data/tokenizers")
d.mkdir(parents=True, exist_ok=True)
Path('/nltk_data/tokenizers/punkt.zip').write_bytes(stream)
# extract punkt.zip
zipfile.ZipFile('/nltk_data/tokenizers/punkt.zip').extractall(
path='/nltk_data/tokenizers/'
)
# check file contents in /nltk_data/tokenizers/
# print(os.listdir("/nltk_data/tokenizers/punkt"))
nltk.word_tokenize("some text here")我从pyodide维护人员和https://github.com/pyodide/pyodide/issues/1798的其他优秀人员那里得到了很多帮助来解决这个问题。谢谢!
https://stackoverflow.com/questions/68835360
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号