
如何在Azure数据流中返回2D数组中的值?
如何在Azure数据流中返回2D数组中的值?
提问于 2021-08-20 20:05:21
背景: CSV文件中有一个列,该列包含给定行的标记列表。标记列表不是按任何特定顺序排列的,列中的每个单元格都不同。我正在寻找与字符串“所有者”匹配的行的值。当拉入CSV文件时,每个单元格的整个单元格是一个字符串。该列中的示例单元格如下所示:
"Organization": "Microsoft", "Owner": "Eric Holmes", "DateCreated": "07/09/2021"目标:I希望在Azure数据流或Azure Data中找到一种方法,为列表中的特定键创建一个带有值的新列。
示例:
电流列
Tags
"Department": "Business", "Owner": "Karen Singh", "DateCreated": "09/20/2019"
"Owner": "Henry Francis", "AppName": "physics-engine", "Department": "GeospatialServices"
"Department": "Fashion", "DateCreated": "01/10/2015", "Owner": "Xiuxiang Long"想要的列
Owner
"Karen Singh"
"Henry Francis"
"Xiuxiang Long"工作到目前为止,:我已经将标记列中的每个字符串拆分成一个数组,方法是拆分它和逗号(,)。然后,我将每个索引处的每个字符串拆分为冒号(:)。这使得这些值看起来像:
Tags
[["Department", "Business"], ["Owner", "Karen Singh"], ["DateCreated", "09/20/2019"]]
[["Owner", "Henry Francis"], ["AppName", "physics-engine"], ["Department", "GeospatialServices"]]
[[Department", "Fashion"], ["DateCreated", "01/10/2015"], ["Owner", "Xiuxiang Long"]]要拆分字符串,我使用了以下打开的表达式
mapIndex(split(replace(Tags, '"', ''), ','), split(#item, ':'))Problems I是开放表达式、Azure数据工厂和数据流的新手。有没有人知道我会:
- 搜索所需的标记,如“所有者”
- ,并返回与其关联的值
。
对不起,我知道这个问题听起来很简单,但是只使用开放的表达式函数会使这个问题变得比必要的复杂。此外,如果有一个更好的方法来解决这个问题,我将感谢任何意见!我一直把头撞在墙上任何线索都能帮上忙。谢谢!
回答 1
Stack Overflow用户
发布于 2021-08-26 04:24:03
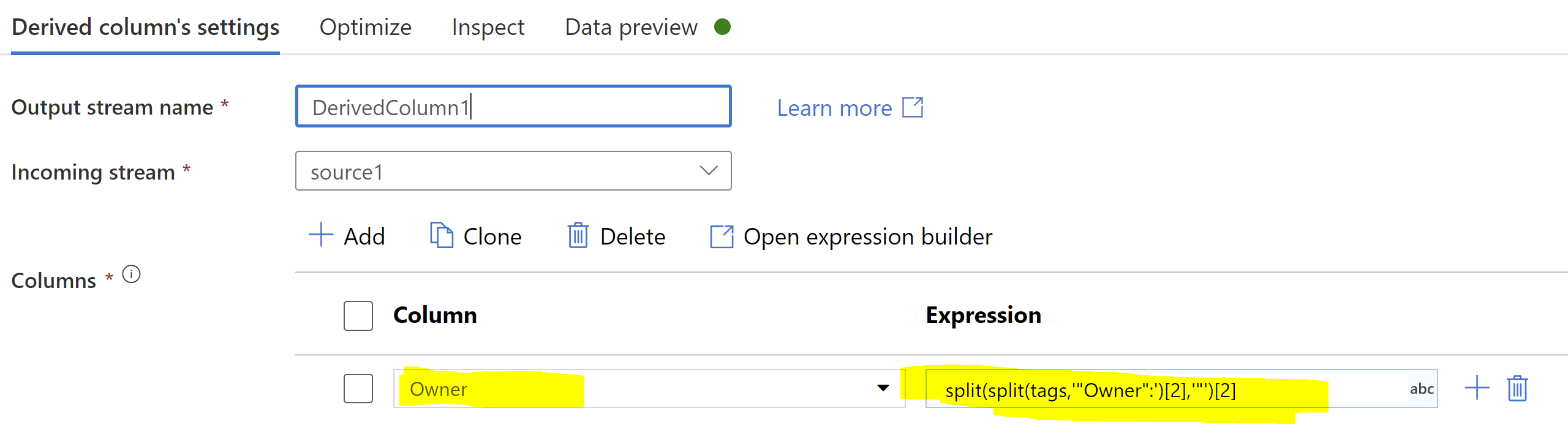
我尝试过复制它,可以使用派生列实现它,在该列中您可以拆分():
使用派生列转换,并使用以下表达式:
split(split(tags,'"Owner":')[2],'"')[2]
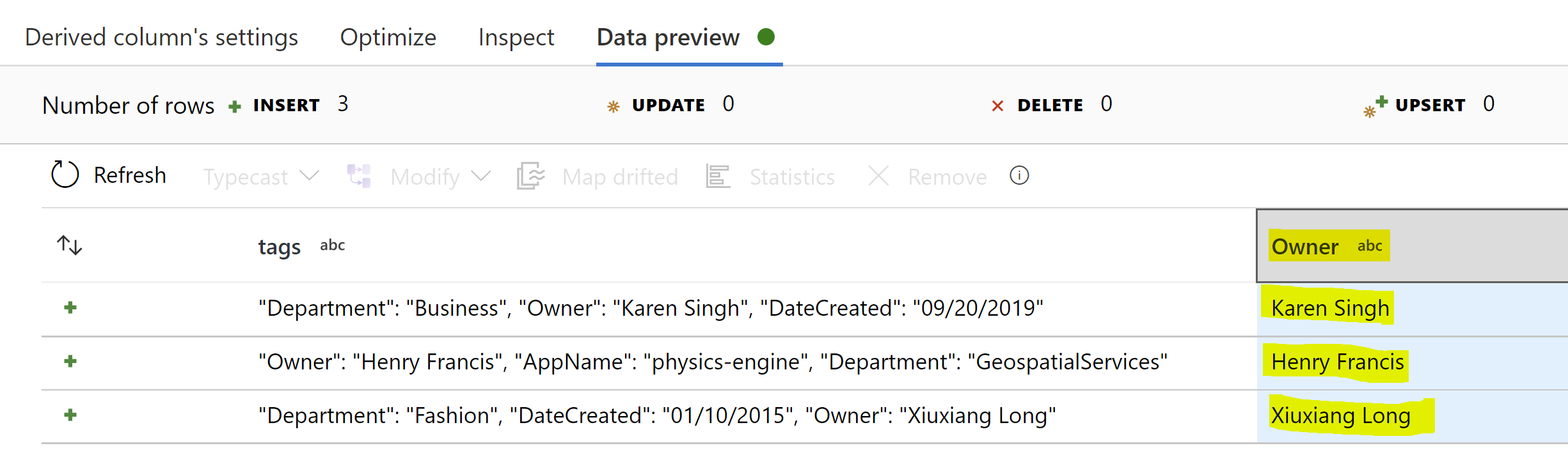
数据预览:
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/68867564
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号