
如何从混合效应to模型中提取随机拦截
如何从混合效应to模型中提取随机拦截
提问于 2021-08-31 22:03:46
我正在尝试使用和multilevelmod从tidymodels中提取lme4随机拦截。我可以使用下面的lme4来完成这个任务:
使用R和lme4的lme4:
library("tidyverse")
library("lme4")
# set up model
mod <- lmer(Reaction ~ Days + (1|Subject),data=sleepstudy)
# create expanded df
expanded_df <- with(sleepstudy,
data.frame(
expand.grid(Subject=levels(Subject),
Days=seq(min(Days),max(Days),length=51))))
# create predicted df with **random intercepts**
predicted_df <- data.frame(expanded_df,resp=predict(mod,newdata=expanded_df))
predicted_df
# plot intercepts
ggplot(predicted_df,aes(x=Days,y=resp,colour=Subject))+
geom_line()
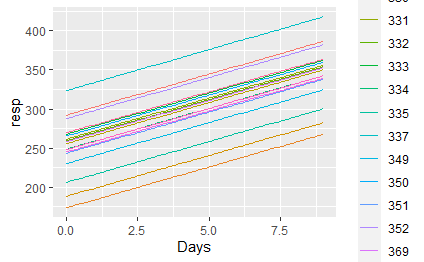
使用tidymodel的:
# example from
# https://github.com/tidymodels/multilevelmod
library("multilevelmod")
library("tidymodels")
library("tidyverse")
library("lme4")
#> Loading required package: parsnip
data(sleepstudy, package = "lme4")
# set engine to lme4
mixed_model_spec <- linear_reg() %>% set_engine("lmer")
# create model
mixed_model_fit_tidy <-
mixed_model_spec %>%
fit(Reaction ~ Days + (1 | Subject), data = sleepstudy)
expanded_df_tidy <- with(sleepstudy,
data.frame(
expand.grid(Subject=levels(Subject),
Days=seq(min(Days),max(Days),length=51))))
predicted_df_tidy <- data.frame(expanded_df_tidy,resp=predict(mixed_model_fit_tidy,new_data=expanded_df_tidy))
ggplot(predicted_df_tidy,aes(x=Days,y=.pred,colour=Subject))+
geom_line()
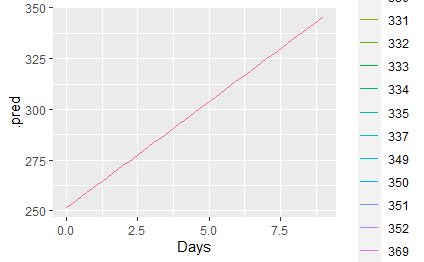
使用predict()函数似乎只给出了固定的效果预测。
有办法从tidymodel和多层次not中提取随机拦截吗?我知道这个包还在开发中,所以在这个阶段可能是不可能的。
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-08-31 23:01:23
我认为你可以这样做:
predicted_df_tidy <- mutate(expanded_df_tidy,
.pred = predict(mixed_model_fit_tidy,
new_data=expanded_df_tidy,
type = "raw", opts=list(re.form=NULL)))- 在某些情况下,
bind_cols()而不是mutate()可能有用吗? - 问题是
multilevelmod内部将预测的默认值设置为re.form = NA;上面的代码将其重置为re.form = NULL(这是lme4的默认值,即在预测中包含所有随机效应)。
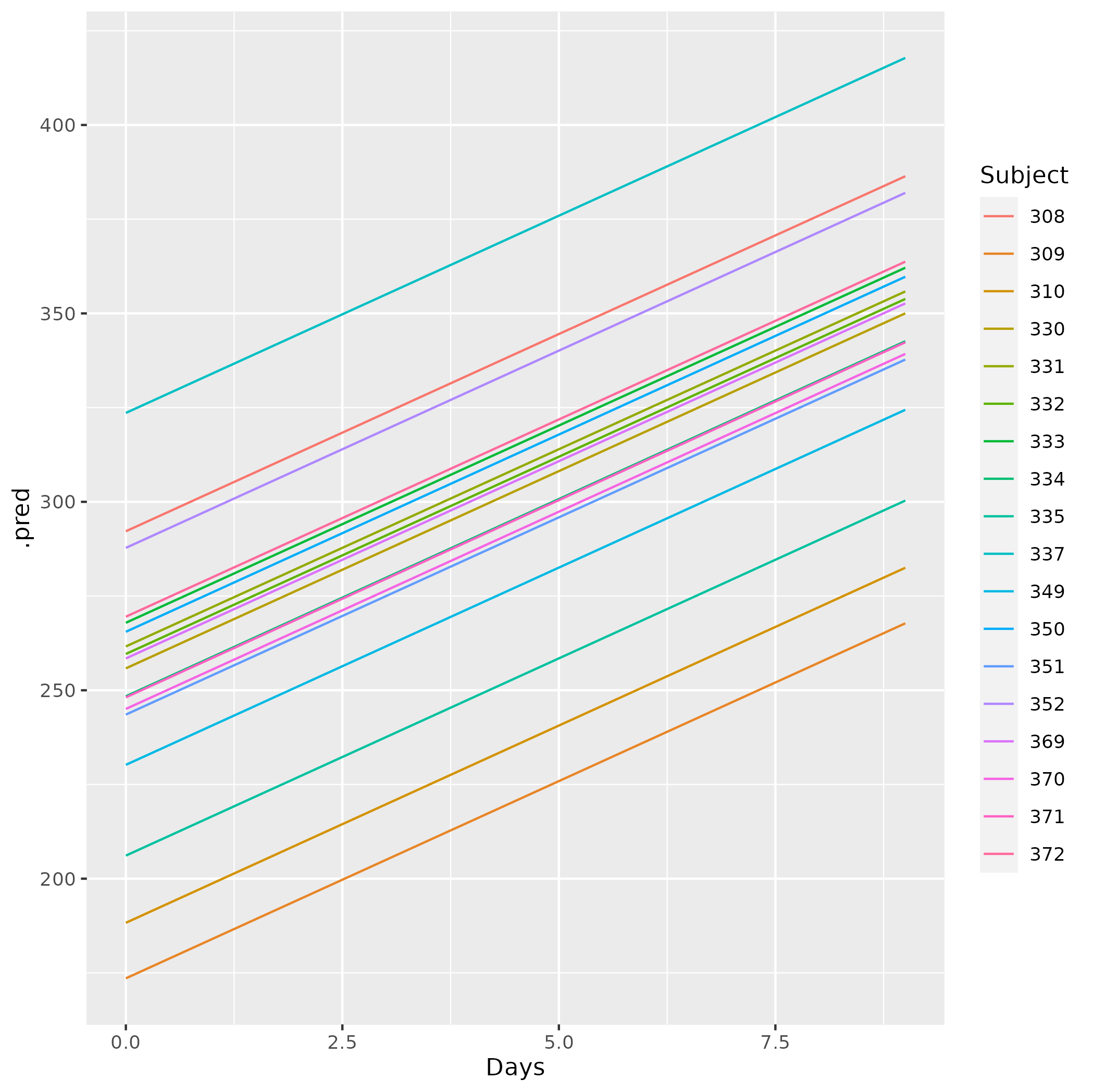
如果你真的想要随机截取(仅),我想你可以predicted_df_tidy %>% filter(Days==0)
如果你想在这方面更“整洁”,我想你可以用purrr::cross_df()代替expand.grid,直接把结果输送到mutate() .
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/69005765
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号