
嵌套数据数据中的多级查找值
嵌套数据数据中的多级查找值
提问于 2021-09-02 20:51:35
我有以下数据:
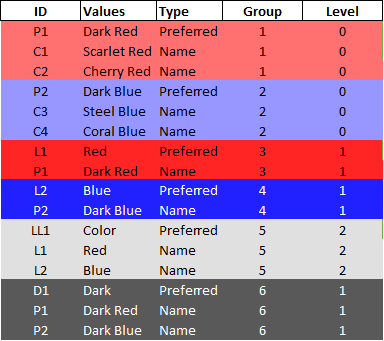
不同的红色颜色(第1-3行)被分组为“暗红色”。他们是“红色”集团(7-8)和“黑暗”集团(14-16)的一部分。“红色”组(7-8)引用了另一个组:“颜色”(11-13)。
目标是为每个“值”获取所有引用组的列表。
示例:
输入:"Scarlet Red"
预期产出:['Scarlet Red', 'Dark Red', 'Red', 'Dark', 'Color']
样本数据:
import pandas as pd
d = {'ID': {0: 'P1', 1: 'C1', 2: 'C2', 3: 'P2', 4: 'C3', 5: 'C4', 6: 'L1', 7: 'P1', 8: 'L2', 9: 'P2', 10: 'LL1', 11: 'L1', 12: 'L2', 13: 'D1', 14: 'P1', 15: 'P2'}, 'Values': {0: 'Dark Red', 1: 'Scarlet Red', 2: 'Cherry Red', 3: 'Dark Blue', 4: 'Steel Blue', 5: 'Coral Blue', 6: 'Red', 7: 'Dark Red', 8: 'Blue', 9: 'Dark Blue', 10: 'Color', 11: 'Red', 12: 'Blue', 13: 'Dark', 14: 'Dark Red', 15: 'Dark Blue'}, 'Type': {0: 'Preferred', 1: 'Name', 2: 'Name', 3: 'Preferred', 4: 'Name', 5: 'Name', 6: 'Preferred', 7: 'Name', 8: 'Preferred', 9: 'Name', 10: 'Preferred', 11: 'Name', 12: 'Name', 13: 'Preferred', 14: 'Name', 15: 'Name'}, 'Group': {0: 1, 1: 1, 2: 1, 3: 2, 4: 2, 5: 2, 6: 3, 7: 3, 8: 4, 9: 4, 10: 5, 11: 5, 12: 5, 13: 6, 14: 6, 15: 6}, 'Level': {0: 0, 1: 0, 2: 0, 3: 0, 4: 0, 5: 0, 6: 1, 7: 1, 8: 1, 9: 1, 10: 2, 11: 2, 12: 2, 13: 1, 14: 1, 15: 1}}
df = pd.DataFrame(d)当前方法:
# get the preferred names
df_pref = df[df['Type'].eq('Preferred')][['Values', 'Group']].rename(columns={'Values': 'Preferred'})
df_merge = df.merge(df_pref, on=['Group'], how='left')
def find_higher_levels(search):
# search = 'Scarlet Red'
lst = [search]
previous_search = None
while search != previous_search:
previous_search = search
search = df_merge[df_merge['Values'].eq(search)]['Preferred'].iloc[-1]
lst.append(search)
return lst
find_higher_levels('Scarlet Red')
# Out[85]: ['Scarlet Red', 'Dark Red', 'Dark', 'Dark']注意:即使函数按预期工作,我也必须将其映射到“值”中的每个值。我的问题是,是否有更明智的方法来解决这个问题。
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-09-03 01:41:09
我用networx库解决了这个问题:
样本数据:
import pandas as pd
df = pd.DataFrame({'ID': {0: 'Dark Red', 1: 'Scarlet Red', 2: 'Cherry Red', 3: 'Dark Blue', 4: 'Steel Blue', 5: 'Coral Blue', 6: 'Red', 7: 'Dark Red', 8: 'Blue', 9: 'Dark Blue', 10: 'Color', 11: 'Red', 12: 'Blue', 13: 'Dark', 14: 'Dark Red', 15: 'Dark Blue'}, 'Start': {0: 'P1', 1: 'C1', 2: 'C2', 3: 'P2', 4: 'C3', 5: 'C4', 6: 'L1', 7: 'P1', 8: 'L2', 9: 'P2', 10: 'LL1', 11: 'L1', 12: 'L2', 13: 'D1', 14: 'P1', 15: 'P2'}, 'End': {0: 'P1', 1: 'P1', 2: 'P1', 3: 'P2', 4: 'P2', 5: 'P2', 6: 'L1', 7: 'L1', 8: 'L2', 9: 'L2', 10: 'LL1', 11: 'LL1', 12: 'LL1', 13: 'D1', 14: 'D1', 15: 'D1'}})
dct = df.set_index('Start')['ID'].to_dict() # translate nodes to their names later on代码:
import networkx as nx
G = nx.Graph()
G = nx.from_pandas_edgelist(df, 'Start', 'End', create_using=nx.DiGraph())
T = nx.dfs_tree(G, source='C1').reverse()
print([dct.get(x) for x in T])
# Out: ['Scarlet Red', 'Dark Red', 'Red', 'Color', 'Dark']页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/69036871
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号