
基于字段值的mysql数据排序
基于字段值的mysql数据排序
提问于 2021-09-04 21:25:01
这是我有的查询
SELECT p1.*, COUNT(p2.id) AS before_me_same_priority
FROM priorities AS p1
LEFT JOIN priorities AS p2 ON p1.priority = p2.priority AND p1.id > p2.id
GROUP BY p1.id
ORDER BY before_me_same_priority, priority
;我想要实现的是:,我需要的是一个先具有优先级1的数据,然后一个优先级为2的数据,然后是优先级3的数据,然后当没有任何其他优先级的数据时,它应该被重复作为优先级1、2和3等等。
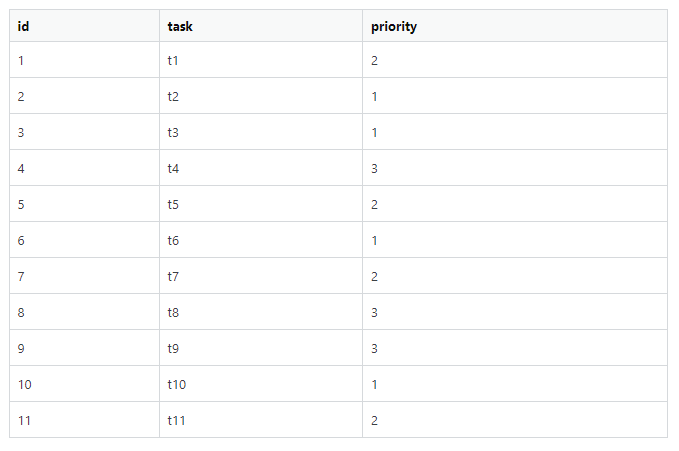
上面的查询工作非常好,但是由于表中有超过30k的数据,所以查询在10到15分钟内完成并加载。我们能做点更快的事吗?
期望的
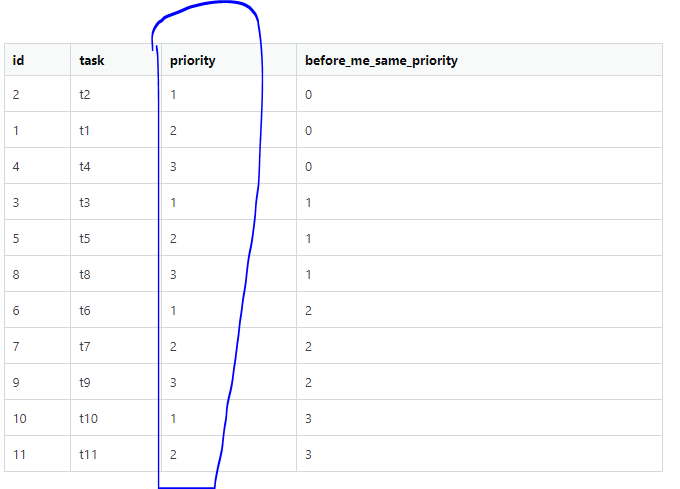
我在ID和优先级方面有主。静态查询非常慢。
回答 2
Stack Overflow用户
发布于 2021-09-04 21:37:23
您应该在优先级字段上创建索引(或键)。p2.id的情况相同,如果情况尚未如此
Stack Overflow用户
发布于 2021-09-04 22:54:04
优先级字段的索引将有所帮助。一个关于优先级和id的两列索引,按照这个顺序,会有更多的帮助。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/69059044
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号